XML: Bài 1.4. Cú pháp XML
Trong bài học này, Cú pháp XML, bạn sẽ học cách:
- Nêu và mô tả việc sử dụng các chú thích và hướng dẫn xử lý trong XML.
- Phân loại dữ liệu ký tự được ghi giữa các thẻ.
- Mô tả các thực thể, khai báo DOCTYPE và thuộc tính.
1.4.1. Comment
Comment XML được sử dụng để mọi người cung cấp thông tin về mã khi không có nhà phát triển. Nó làm cho một tài liệu dễ đọc hơn. Chú thích không bị giới hạn đối với các định nghĩa loại tài liệu nhưng có thể được đặt ở bất kỳ đâu trong tài liệu. Nhận xét trong XML tương tự như trong HTML. Nhận xét chỉ nên được sử dụng khi cần thiết, vì chúng không được xử lý. Nhận xét chỉ được sử dụng cho nhu cầu của con người hơn là máy tính. Vì các nhận xét không được phân tích cú pháp, sự hiện diện hay vắng mặt của chúng không tạo ra bất kỳ sự khác biệt nào đối với bộ xử lý.
Chúng được chèn vào tài liệu XML và không phải là một phần của mã XML. Chúng có thể xuất hiện trong phần mở đầu tài liệu, DTD hoặc trong nội dung văn bản. Những nhận xét này sẽ không xuất hiện bên trong các thẻ hoặc giá trị thuộc tính.
Các chú thích bắt đầu bằng chuỗi <!-- và kết thúc bằng chuỗi -->. Trình phân tích cú pháp tin rằng nhận xét đã kết thúc khi nó tìm thấy dấu > như trong hình 1.8.
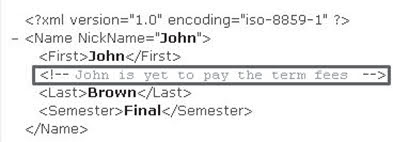
Hình 1.8: Nhận xét trong Tài liệu XML
Comment được viết bằng cách tuân theo một số quy tắc.
Ø Quy tắc
Các quy tắc phải tuân theo khi viết bình luận như sau:
- Nhận xét không được chứa "-" hoặc "—" vì nó có thể dẫn đến nhầm lẫn trình phân tích cú pháp XML.
- Nhận xét không được đặt trong thẻ hoặc khai báo thực thể.
- Chú thích không nên được đặt trước khai báo XML.
- Nhận xét có thể được sử dụng để nhận xét các bộ thẻ.
Đoạn mã sau minh họa một ví dụ,
<!-- Highlight these <ChiefGuest1> King </ChiefGuest1> <Judge>Queen</Judge> -->
- Nhận xét không nên được lồng vào nhau.
Đoạn mã sau minh họa một ví dụ về nhận xét,
Đoạn mã:
<Name NickName=’John’> <First>John</First> <!--John is yet to pay the term fees--> <Last>Brown</Last> <Semester>Final</Semester> </Name>
1.4.2. Hướng dẫn xử lý
Hướng dẫn xử lý là thông tin dành riêng cho ứng dụng. Các hướng dẫn này không tuân theo các quy tắc XML hoặc cú pháp nội bộ. Với sự trợ giúp của trình phân tích cú pháp, các hướng dẫn này sẽ được chuyển đến ứng dụng. Ứng dụng có thể sử dụng các hướng dẫn xử lý hoặc chuyển chúng sang một ứng dụng khác.
Mục tiêu chính của hướng dẫn xử lý là trình bày một số hướng dẫn đặc biệt cho ứng dụng.
Tất cả các hướng dẫn xử lý phải bắt đầu bằng <? và kết thúc bằng ?>.
Mặc dù một khai báo XML cũng bắt đầu bằng <? và kết thúc bằng?>, nó không được coi là một quá trình xử lý chỉ dẫn. Đó là vì một khai báo XML chỉ cung cấp thông tin cho trình phân tích cú pháp chứ không phải cho ứng dụng. Trong một số trường hợp, ứng dụng có thể chỉ cần thông tin trong hướng dẫn xử lý nếu nó hiển thị đầu ra cho người dùng.
Cú pháp:
<?PITarget <instruction>?>
trong đó,
PITarget là tên của ứng dụng sẽ nhận được hướng dẫn xử lý.
<instruction> là hướng dẫn cho ứng dụng.
Đoạn mã sau minh họa một ví dụ về lệnh xử lý.
Đoạn mã:
<Name NickName=’John’> <First>John</First> <!--John is yet to pay the term fees--> <Last>Brown</Last> <?feesprocessor SELECT fees FROM STUDENTFEES?> <Semester>Final</Semester> </Name>
trong đó,
bộ xử lý phí là tên của ứng dụng nhận lệnh xử lý.
SELECT fees FROM STUDENTFEES là hướng dẫn.
1.4.3. Phân loại dữ liệu ký tự
Một tài liệu XML được chia thành dữ liệu đánh dấu và dữ liệu ký tự.
Dữ liệu ký tự mô tả nội dung thực tế của tài liệu với khoảng trắng. Văn bản trong dữ liệu ký tự không được trình phân tích cú pháp xử lý và do đó, không được coi là văn bản thông thường. Dữ liệu ký tự có thể được phân loại thành:
- CDATA
- PCDATA
1.4.4. PCDATA
Dữ liệu được phân tích cú pháp bởi trình phân tích cú pháp được gọi là dữ liệu ký tự được phân tích cú pháp (Parsed Character DATA - PCDATA). PCDATA chỉ định rằng phần tử đã phân tích cú pháp dữ liệu ký tự. Nó được sử dụng trong khai báo phần tử.
Ký tự thoát như "<" khi được sử dụng trong tài liệu XML sẽ khiến trình phân tích cú pháp diễn giải nó như một phần tử mới. Kết quả là nó sẽ tạo ra một lỗi như hình 1.9.

Hình 1.9: Lỗi đầu ra
Đoạn mã sau minh họa một ví dụ về PCDATA.
Đoạn mã:
<Name nickname=’John’> <First>John</First> <!--John is yet to pay the term fees--> <Last>Brown</Last> <Semester>Final> 10 & <20</Semester> </Name>
1.4.5. CDATA
CDATA là viết tắt của dữ liệu ký tự (Character DATA) có các ký tự dành riêng và khoảng trắng trong đó. Mặc dù văn bản bên trong CDATA không được phân tích cú pháp bởi trình phân tích cú pháp, nó thường được sử dụng cho mã kịch bản. Trình phân tích cú pháp XML bỏ qua tất cả các thẻ và tham chiếu thực thể bên trong các khối CDATA. Khối CDATA chỉ ra cho trình phân tích cú pháp rằng nó chỉ là một văn bản chứ không phải là một đánh dấu. Một khối CDATA luôn bắt đầu bằng dấu phân cách <! [CDATA[ và kết thúc bằng dấu phân cách ]]>. Vì dấu phân cách kết thúc đánh dấu phần cuối của khối CDATA, nên chuỗi ký tự ]]/ không được phép ở giữa khối CDATA. Điều này sẽ báo hiệu sự kết thúc của phần CDATA.
Cú pháp của CDATA như sau:
<![CDATA[ data ]]>
Đoạn mã sau minh họa một ví dụ về CDATA.
Đoạn mã:
<Sample> <![CDATA[ <Document> <Name>Core XML</Name> <Company>Aptech</Company> </Document>]]> </Sample>
1.4.6. Thực thể
Tài liệu XML được tạo thành từ một lượng lớn thông tin được gọi là các thực thể. Các thực thể được sử dụng để tránh nhập nhiều đoạn văn bản dài liên tục trong tài liệu. Chúng có thể được phân loại thành những loại sau:- Các thực thể ký tự: Chúng tạo thành cơ chế, được sử dụng thay cho dạng chữ của ký tự. Chúng cung cấp ý nghĩa của '>' khi biểu tượng '>' được đánh máy. Các thực thể ký tự cũng có thể được sử dụng với các giá trị thập phân hoặc thập lục phân với điều kiện là các số hỗ trợ mã hóa Unicode. Một chương trình xử lý XML thay thế các thực thể ký tự bằng các ký tự tương đương của chúng.
- Các thực thể nội dung: Các thực thể này được sử dụng để thay thế các giá trị nhất định. Chúng tương tự như macro thay thế văn bản trong các ngôn ngữ lập trình như C. Thực thể nội dung có cú pháp sau:
<!Entity name value>
- Các đơn vị chưa phân tích: Những đơn vị này khi được sử dụng sẽ tắt quá trình phân tích cú pháp. Chúng có thể được sử dụng để đưa nội dung đa phương tiện vào tài liệu XML.
Mọi thực thể bao gồm một tên và một giá trị. Giá trị nằm trong khoảng từ một ký tự đến tệp đánh dấu XML. Khi tài liệu XML được phân tích cú pháp, nó sẽ kiểm tra các tham chiếu thực thể. Đối với mọi tham chiếu thực thể, trình phân tích cú pháp sẽ kiểm tra bộ nhớ để thay thế tham chiếu thực thể bằng văn bản hoặc đánh dấu.
Tham chiếu thực thể bao gồm dấu và (&), tên thực thể và dấu chấm phẩy (;).
Tất cả các thực thể phải được khai báo trước khi chúng được sử dụng trong tài liệu. Một thực thể có thể được khai báo trong phần mở đầu tài liệu hoặc trong DTD.
Một số thực thể được xác định trong hệ thống và được gọi là các thực thể được xác định trước. Các thực thể này được mô tả trong bảng 1.2.
|
Thực thể được xác định trước |
Mô tả |
Đầu ra |
|---|---|---|
|
< |
Tạo dấu ngoặc nhọn bên trái |
< |
|
> |
Tạo dấu ngoặc nhọn bên phải |
> |
|
& |
Tạo dấu và |
& |
|
' |
Tạo một ký tự trích dẫn duy nhất (nháy đơn) |
' |
|
" |
Tạo một ký tự dấu ngoặc kép |
" |
Bảng 1.2: Thực thể
Đoạn mã sau minh họa một ví dụ về các thực thể.
Đoạn mã:
<?xml version="1.0"?> <!DOCTYPE Letter [ <!ENTITY address "15 Downing St Floor 1"> <!ENTITY city "New York"> ]> <Letter> <To>"Tom Smith"</To> <Address>&address;</Address> <City>&city;</City> <Body> Hi! How are you? The sum is > $1000 </Body> <From>ARNOLD</From> </Letter>
1.4.7. Danh mục thực thể
Các thực thể được sử dụng làm lối tắt để tham chiếu đến các trang dữ liệu. Hình 1.10 cho thấy các loại thực thể.

Hình 1.10: Các danh mục thực thể
Hai loại thực thể như sau:
Ø Thực thể chung
Đây là các thực thể được sử dụng trong nội dung tài liệu. Các thực thể chung có thể được khai báo bên trong hoặc bên ngoài. Các tham chiếu cho các thực thể chung bắt đầu bằng dấu và (&) và kết thúc bằng dấu chấm phẩy (;). Tên của thực thể có trong hai ký tự này.
Mọi thực thể chung nội bộ đều được xác định trong DTD. Nó được khai báo với từ khóa <! ENTITY>. Cú pháp như sau:
<!ENTITY Name "text that is to replaced">
trong đó,
Name: giá trị cho văn bản sẽ được thay thế.
Các thực thể bên ngoài tham chiếu đến các đơn vị lưu trữ bên ngoài tài liệu có chứa phần tử gốc. Sử dụng tham chiếu thực thể bên ngoài, các thực thể bên ngoài có thể được nhúng vào bên trong tài liệu. Tham chiếu thực thể bên ngoài chỉ ra vị trí mà trình phân tích cú pháp sẽ chèn thực thể bên ngoài vào tài liệu. Thực thể bên ngoài có Bộ định vị tài nguyên thống nhất (URL) trong khai báo của nó; URL được chỉ định cho biết tài liệu có văn bản của thực thể. Cú pháp như sau:
<!ENTITY Name SYSTEM "URL">
Đoạn mã sau đây minh họa một ví dụ về thực thể chung.
Đoạn mã:
<!DOCTYPE MusicCollection [ <!ENTITY R "Rock"> <!ENTITY S "Soft"> <!ENTITY RA "Rap"> <!ENTITY HH "Hiphop"> <!ENTITY F "Folk"> ]>
Ø Thực thể tham số
Các loại thực thể này chỉ được sử dụng trong DTD. Các loại thực thể này được khai báo trong DTD. Cả hai thực thể tham số bên trong và bên ngoài không được sử dụng trong nội dung của tài liệu XML vì bộ xử lý không nhận ra chúng. Thực thể tham số được định dạng tốt tương tự như thực thể chung, ngoại trừ việc nó sẽ bao gồm chỉ định%. Tham chiếu cũng tương tự như tham chiếu thực thể chung.
Tham chiếu đến các thực thể này được thực hiện bằng cách sử dụng dấu phần trăm (%) và dấu chấm phẩy (;) làm dấu phân cách. Đoạn mã sau minh họa một ví dụ về thực thể tham số.
Đoạn mã:
<!ENTITY % ADDRESS "text that is to be represented by an entity">
Thực thể tham số được định dạng tốt sẽ trông giống như một thực thể chung, ngoại trừ việc nó sẽ bao gồm từ chỉ định "%".
1.4.8. Khai báo Doctype
Khai báo loại tài liệu xác định các phần tử sẽ được sử dụng trong tài liệu.Khai báo loại tài liệu được khai báo để chỉ ra DTD mà tài liệu tuân theo. Nó có thể được khai báo trong tài liệu XML hoặc có thể tham chiếu đến tài liệu bên ngoài.
Cú pháp:
Cú pháp khai báo loại tài liệu như sau:
<! DOCTYPE name_of_root_element SYSTEM "URL of the external DTD subset" [ Internal DTD subset ]>
trong đó,
name_of_root_element là tên của phần tử gốc.
SYSTEM là URL nơi đặt DTD.
[Internal DTD subset] là những khai báo có trong tài liệu.
Đoạn mã sau minh họa một ví dụ về khai báo kiểu tài liệu.
Đoạn mã:
<?xml version="1.0" encoding="ISO-8859-1"?> <!DOCTYPE program SYSTEM "HelloJimmy.dtd"> <Program> <Comments> This is a simple Java Program. It will display the message "Hello Jimmy,How are you?" on execution. </Comments> <Code> public static void main(String[] args) { System.out.println("Hello Jimmy,How are you?"); // Display the string. } } </Code> </Program>
Tệp DTD :
<!ELEMENT Program (comments, code)> <!ELEMENT Comments (#PCDATA)> <!ELEMENT Code (#PCDATA)>
Kết quả được hiển thị trong hình 1.11.

Hình 1.11: Đầu ra sau khi áp dụng DTD
1.4.9. Các thuộc tính
Các thuộc tính là một phần của các phần tử. Chúng cung cấp thông tin về phần tử và được nhúng trong thẻ bắt đầu phần tử. Một thuộc tính bao gồm tên thuộc tính và giá trị thuộc tính. Tên luôn đứng trước giá trị của nó, chúng được phân tách bằng dấu bằng. Giá trị thuộc tính được đặt trong dấu ngoặc kép để phân định nhiều thuộc tính trong cùng một phần tử. Một thuộc tính có thể là CDATA, ENTITY, ENUMERATION, ID, IDREF, NMTOKEN hoặc NOTATION.
Giá trị thuộc tính được liệt kê được sử dụng khi các giá trị thuộc tính phải là một trong một tập hợp giá trị pháp lý cố định. Thuộc tính của loại số nhận dạng (ID) phải là duy nhất. Nó được sử dụng để tìm kiếm một thể hiện cụ thể của một phần tử. Mỗi phần tử chỉ có thể có một thuộc tính của loại ID. IDREF cũng là một loại định danh và nó chỉ nên trỏ đến một phần tử. Các thuộc tính IDREF có thể được sử dụng để tham chiếu đến một phần tử từ các phần tử khác. Thuộc tính kiểu NMTOKEN cho phép bất kỳ sự kết hợp nào của các ký tự mã thông báo tên. Các ký tự có thể là chữ cái, số, dấu chấm, dấu gạch ngang, dấu hai chấm hoặc dấu gạch dưới. Thuộc tính kiểu NMTOKENS cho phép nhiều giá trị nhưng được phân tách bằng khoảng trắng. Thuộc tính kiểu NOTATION phải tham chiếu đến một ký hiệu được khai báo ở nơi khác trong DTD. Một khai báo cũng có thể là một ví dụ cho một danh sách các ký hiệu.
Cú pháp:
<elementName attName1="attValue2" attName2="attValue2"...>
Đoạn mã sau minh họa một ví dụ về các thuộc tính.
Đoạn mã:
<?xml version="1.0" ?> <Player Sex="male"> <FirstName>Tom</FirstName> <LastName>Federer</LastName> </Player>
Các thuộc tính có một số hạn chế như sau:
- Không giống như các phần tử con, chúng không chứa nhiều giá trị và không mô tả cấu trúc.
- Chúng không thể mở rộng cho những thay đổi trong tương lai.
- Chúng không dễ dàng bị thao túng bởi mã.
- Chúng không dễ dàng để kiểm tra đối với một DTD.
Kiểm tra kiến thức bài 1.4
1. Câu nào sau đây đúng trong trường hợp chú thích và hướng dẫn xử lý trong XML?
|
(A) |
Nhận xét được xử lý bởi bộ xử lý. |
|
(B) |
Nhận xét chỉ xuất hiện trong phần mở đầu tài liệu. |
|
(C) |
Hướng dẫn xử lý dành riêng cho ứng dụng. |
|
(D) |
Hướng dẫn xử lý được chuyển tới đích. |
|
(E) |
</ PITarget <instruction> /> là một lệnh xử lý. |
2. Câu lệnh nào sau đây hợp lệ với dữ liệu ký tự trong XML?
|
(A) |
Dữ liệu ký tự được coi như văn bản thông thường. |
|
(B) |
Các ký tự như ">" và "&" có thể được sử dụng trong các phần PCDATA. |
|
(C) |
Các ký tự như ">" và "&" có thể được sử dụng trong các phần CDATA. |
|
(D) |
CDATA bắt đầu bằng "<! [CDATA [" và kết thúc bằng "]]>". |
|
(E) |
Các thực thể tham số sử dụng dấu và (&) và dấu chấm phẩy (;) làm dấu phân cách. |
Tóm tắt Bài học số 1
Trong mô-đun 1 này, Giới thiệu về XML, bạn đã học về:
Ø Giới thiệu về XML
XML được phát triển để khắc phục những hạn chế của các ngôn ngữ đánh dấu trước đó. XML bao gồm tập hợp các quy tắc mô tả nội dung được hiển thị trong tài liệu. Đánh dấu XML chứa nội dung trong các vùng chứa thông tin được gọi là phần tử.
Ø Khám phá XML
Tài liệu XML được chia thành hai phần cụ thể là phần mở đầu tài liệu và phần tử gốc. Trình soạn thảo XML tạo tài liệu XML và trình phân tích cú pháp xác nhận tài liệu.
Ø Làm việc với XML
Tài liệu XML được chia thành Tuyên bố phiên bản XML, DTD và cá thể tài liệu trong đó đánh dấu xác định nội dung. Đánh dấu XML một lần nữa được phân loại thành cấu trúc, ngữ nghĩa và phong cách. Đầu ra của tài liệu XML được hiển thị trong trình duyệt nếu nó được định dạng tốt.
Ø Cú pháp XML
Chú thích được sử dụng trong tài liệu để cung cấp thông tin về dòng hoặc khối mã. Nội dung trong tài liệu XML được chia thành dữ liệu đánh dấu và dữ liệu ký tự. Các thực thể trong XML được chia thành các thực thể chung và các thực thể tham số. Một DTD có thể được khai báo bên trong hoặc bên ngoài.