Python: Nhận diện khuôn mặt theo cách truyền thống với Python
Mục lục
- Nhận diện khuôn mặt là gì?
- Làm thế nào để Máy tính "Xem" Hình ảnh?
- Tính năng là gì?
- Chuẩn bị
- Framework phát hiện đối tượng Viola-Jones
- Đọc thêm
- Kết luận
Thị giác máy tính là một lĩnh vực thú vị và đang phát triển. Có rất nhiều vấn đề thú vị cần giải quyết! Một trong số đó là nhận diện khuôn mặt: khả năng máy tính nhận ra một bức ảnh có khuôn mặt người và cho bạn biết vị trí của nó. Trong bài viết này, bạn sẽ tìm hiểu về tính năng nhận diện khuôn mặt với Python.
Để phát hiện bất kỳ đối tượng nào trong một hình ảnh, cần phải hiểu cách hình ảnh được biểu diễn bên trong máy tính và đối tượng đó khác biệt trực quan như thế nào với bất kỳ đối tượng nào khác.
Sau khi hoàn tất, quá trình quét hình ảnh và tìm kiếm các dấu hiệu trực quan đó cần phải được tự động hóa và tối ưu hóa. Tất cả các bước này kết hợp với nhau để tạo thành một thuật toán thị giác máy tính nhanh chóng và đáng tin cậy.
Trong hướng dẫn này, bạn sẽ học:
- Nhận diện khuôn mặt là gì
- Cách máy tính hiểu các tính năng trong hình ảnh
- Cách nhanh chóng phân tích nhiều tính năng khác nhau để đi đến quyết định
- Cách sử dụng giải pháp Python tối thiểu để phát hiện khuôn mặt người trong hình ảnh
Nhận diện khuôn mặt là gì?
Nhận diện khuôn mặt là một loại công nghệ thị giác máy tính có thể nhận dạng khuôn mặt của mọi người trong các hình ảnh kỹ thuật số. Điều này rất dễ dàng đối với con người, nhưng máy tính cần phải được hướng dẫn chính xác và tỉ mỉ. Hình ảnh có thể chứa nhiều vật thể không phải là khuôn mặt người, chẳng hạn như các tòa nhà, ô tô, động vật, v.v.
Nó khác biệt với các công nghệ thị giác máy tính khác liên quan đến khuôn mặt người, như nhận dạng, phân tích và theo dõi khuôn mặt.
Nhận dạng khuôn mặt bao gồm việc xác định khuôn mặt trong ảnh là của người X chứ không phải của người Y. Nó thường được sử dụng cho mục đích sinh trắc học, như mở khóa điện thoại thông minh của bạn.
Phân tích khuôn mặt cố gắng hiểu điều gì đó về mọi người từ các đặc điểm trên khuôn mặt của họ, chẳng hạn như xác định tuổi, giới tính hoặc cảm xúc mà họ đang thể hiện.
Theo dõi khuôn mặt chủ yếu xuất hiện trong phân tích video và cố gắng theo dõi khuôn mặt và các đặc điểm của khuôn mặt (mắt, mũi và môi) từ khung hình này sang khung hình khác. Các ứng dụng phổ biến nhất là các bộ lọc khác nhau có sẵn trong các ứng dụng di động như Snapchat.
Tất cả những vấn đề này đều có các giải pháp công nghệ khác nhau. Hướng dẫn này sẽ tập trung vào một giải pháp truyền thống cho thử thách đầu tiên: nhận diện khuôn mặt.
Làm thế nào để Máy tính "Xem" Hình ảnh?
Phần tử nhỏ nhất của hình ảnh được gọi là pixel hoặc phần tử hình ảnh. Về cơ bản nó là một dấu chấm trong hình. Một hình ảnh chứa nhiều pixel được sắp xếp theo hàng và cột.
Bạn sẽ thường thấy số hàng và cột được biểu thị bằng độ phân giải của hình ảnh. Ví dụ, một TV Ultra HD có độ phân giải 3840x2160, nghĩa là nó rộng 3840 pixel và cao 2160 pixel.
Nhưng máy tính không hiểu pixel là các chấm màu. Nó chỉ hiểu những con số. Để chuyển đổi màu sắc thành số, máy tính sử dụng nhiều mô hình màu sắc khác nhau.
Trong hình ảnh màu, các pixel thường được biểu diễn trong mô hình màu RGB. RGB là viết tắt của Red Green Blue. Mỗi pixel là sự kết hợp của ba màu đó. RGB rất tuyệt vời trong việc mô hình hóa tất cả các màu sắc mà con người cảm nhận được bằng cách kết hợp nhiều màu đỏ, xanh lục và xanh lam.
Vì máy tính chỉ hiểu các con số nên mỗi pixel được biểu thị bằng ba số, tương ứng với lượng màu đỏ, xanh lục và xanh lam có trong pixel đó. Bạn có thể tìm hiểu thêm về không gian màu trong Phân đoạn hình ảnh bằng Không gian màu trong OpenCV + Python.
Trong hình ảnh thang độ xám (đen và trắng), mỗi pixel là một số duy nhất, đại diện cho lượng ánh sáng hoặc cường độ mà nó mang theo. Trong nhiều ứng dụng, phạm vi cường độ là từ 0 (đen) đến 255 (trắng). Tất cả mọi thứ giữa 0 và 255 là các sắc thái khác nhau của màu xám.
Nếu mỗi pixel thang độ xám là một số, thì hình ảnh sẽ tương ứng với một ma trận (hoặc bảng) các số như hình sau:
Ví dụ hình ảnh 3x3 với các giá trị pixel và màu sắc

Trong ảnh màu, có ba ma trận như vậy đại diện cho các kênh đỏ, lục và lam.
Tính năng (Feature) là gì?
Feature là một phần thông tin trong hình ảnh có liên quan đến việc giải quyết một vấn đề nhất định. Nó có thể là một cái gì đó đơn giản như một giá trị pixel đơn lẻ hoặc phức tạp hơn như các cạnh, góc và hình dạng. Bạn có thể kết hợp nhiều tính năng đơn giản thành một tính năng phức tạp.
Việc áp dụng các thao tác nhất định cho một hình ảnh cũng tạo ra thông tin có thể được coi là các tính năng. Thị giác máy tính và xử lý hình ảnh có một bộ sưu tập lớn các tính năng hữu ích và các hoạt động trích xuất tính năng.
Về cơ bản, bất kỳ thuộc tính vốn có hoặc có nguồn gốc nào của hình ảnh đều có thể được sử dụng như một tính năng để giải quyết các nhiệm vụ.
Chuẩn bị (Preparation)
Để chạy các ví dụ về mã lệnh, bạn cần thiết lập một môi trường với tất cả các thư viện cần thiết được cài đặt. Cách đơn giản nhất là sử dụng conda.
Bạn sẽ cần ba thư viện:
scikit-imagescikit-learnopencv
Để tạo một môi trường trong conda, hãy chạy các lệnh sau trong trình bao của bạn:
$ conda create --name face-detection python=3.7
$ source activate face-detection
(face-detection)$ conda install scikit-learn
(face-detection)$ conda install -c conda-forge scikit-image
(face-detection)$ conda install -c menpo opencv3
Nếu bạn gặp sự cố khi cài đặt OpenCV đúng cách và chạy các ví dụ, hãy tham khảo Hướng dẫn cài đặt của họ hoặc bài viết về Hướng dẫn, Tài nguyên và Hướng dẫn OpenCV.
Bây giờ bạn có tất cả các gói cần thiết để thực hành những gì bạn học được trong bài hướng dẫn này.
Framework phát hiện đối tượng Viola-Jones
Thuật toán này được đặt theo tên của hai nhà nghiên cứu thị giác máy tính đã đề xuất phương pháp này vào năm 2001: Paul Viola và Michael Jones.
Họ đã phát triển một khung phát hiện đối tượng chung có thể cung cấp tỷ lệ phát hiện đối tượng cạnh tranh trong thời gian thực. Nó có thể được sử dụng để giải quyết nhiều vấn đề phát hiện, nhưng động lực chính đến từ nhận diện khuôn mặt.
Thuật toán Viola-Jones có 4 bước chính và bạn sẽ tìm hiểu thêm về từng bước trong các phần tiếp theo:
- Chọn các tính năng Haar-Like
- Tạo một hình ảnh tích hợp
- Chạy đào tạo AdaBoost
- Tạo tầng phân loại
Đưa ra một hình ảnh, thuật toán xem xét nhiều tiểu vùng nhỏ hơn và cố gắng tìm một khuôn mặt bằng cách tìm kiếm các đặc điểm cụ thể trong mỗi tiểu vùng. Nó cần phải kiểm tra nhiều vị trí và tỷ lệ khác nhau vì một hình ảnh có thể chứa nhiều khuôn mặt có kích thước khác nhau. Viola và Jones đã sử dụng các tính năng Haar-Like để phát hiện khuôn mặt.
Tính năng Haar-Like
Tất cả các khuôn mặt của con người đều có một số điểm tương đồng. Ví dụ, nếu bạn nhìn vào một bức ảnh chụp khuôn mặt của một người, bạn sẽ thấy vùng mắt tối hơn sống mũi. Vùng má cũng sáng hơn vùng mắt. Chúng ta có thể sử dụng các thuộc tính này để giúp hiểu liệu một hình ảnh có chứa khuôn mặt người hay không.
Một cách đơn giản để tìm ra vùng nào sáng hơn hoặc tối hơn là tổng hợp các giá trị pixel của cả hai vùng và so sánh chúng. Tổng các giá trị pixel trong vùng tối hơn sẽ nhỏ hơn tổng các pixel trong vùng sáng hơn. Điều này có thể được thực hiện bằng cách sử dụng các tính năng Haar-Like.
Tính năng Haar-Like được biểu diễn bằng cách lấy một phần hình chữ nhật của hình ảnh và chia hình chữ nhật đó thành nhiều phần. Chúng thường được hình dung dưới dạng hình chữ nhật liền kề màu đen và trắng:
Các tính năng hình chữ nhật Haar-Like cơ bản
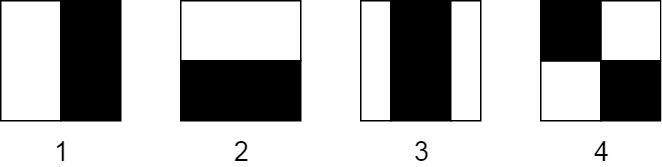
Trong hình ảnh này, bạn có thể thấy 4 loại tính năng Haar-Like cơ bản:
- Tính năng nằm ngang với hai hình chữ nhật
- Tính năng nằm dọc có hai hình chữ nhật
- Tính năng nằm dọc với ba hình chữ nhật
- Tính năng đường chéo với bốn hình chữ nhật
Hai tính năng đầu tiên rất hữu ích để phát hiện các cạnh. Tính năng thứ ba phát hiện các đường và tính năng thứ tư là tốt để tìm các tính năng đường chéo. Nhưng chúng làm việc bằng cách nào?
Giá trị của tính năng được tính bằng một số: tổng giá trị pixel trong vùng màu đen trừ đi tổng giá trị pixel trong vùng trắng. Đối với các khu vực đồng nhất như một bức tường, con số này sẽ gần bằng 0 và sẽ không cung cấp cho bạn bất kỳ thông tin có ý nghĩa nào.
Để trở nên hữu ích, tính năng Haar-Like cần cung cấp cho bạn một số lượng lớn, có nghĩa là các khu vực trong hình chữ nhật đen và trắng rất khác nhau. Có những tính năng đã biết hoạt động rất tốt để phát hiện khuôn mặt người:
Tính năng Haar-Like được áp dụng trên vùng mắt. (Hình ảnh: Wikipedia)

Trong ví dụ này, vùng mắt tối hơn vùng bên dưới. Bạn có thể sử dụng thuộc tính này để tìm vùng nào của hình ảnh cho phản hồi mạnh (số lượng lớn) cho một tính năng cụ thể:
Tính năng Haar-Like được áp dụng trên sống mũi. (Hình ảnh: Wikipedia)

Ví dụ này mang lại phản ứng mạnh mẽ khi áp dụng cho sống mũi. Bạn có thể kết hợp nhiều tính năng này để biết liệu một vùng hình ảnh có chứa khuôn mặt người hay không.
Như đã đề cập, thuật toán Viola-Jones tính toán rất nhiều các tính năng này trong nhiều vùng con của một hình ảnh. Điều này nhanh chóng trở nên tốn kém về mặt tính toán: mất rất nhiều thời gian khi sử dụng tài nguyên hạn chế của máy tính.
Để giải quyết vấn đề này, Viola và Jones đã sử dụng hình ảnh tích phân.
Hình ảnh tích phân
Hình tích phân (còn được gọi là bảng vùng tổng) là tên của cả cấu trúc dữ liệu và thuật toán được sử dụng để có được cấu trúc dữ liệu này. Nó được sử dụng như một cách nhanh chóng và hiệu quả để tính toán tổng các giá trị pixel trong một hình ảnh hoặc một phần hình chữ nhật của hình ảnh.
Trong một hình ảnh tích hợp, giá trị của mỗi điểm là tổng của tất cả các pixel ở trên và ở bên trái, bao gồm cả pixel mục tiêu:
Tính toán một hình ảnh tích hợp từ các giá trị pixel
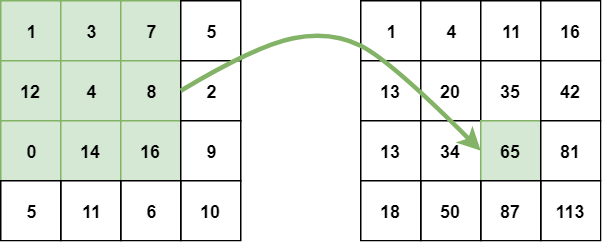
Ảnh tích phân có thể được tính bằng một lần truyền qua ảnh gốc. Điều này làm giảm tổng các cường độ pixel trong một hình chữ nhật vào trong chỉ ba phép toán với bốn con số mà không quan tâm đến kích thước hình chữ nhật:
Tính tổng các điểm ảnh trong hình chữ nhật màu cam.
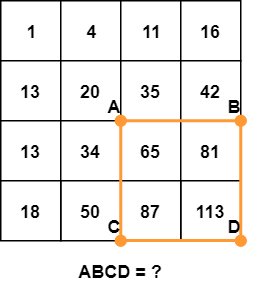
Tổng số pixel trong hình chữ nhật ABCD có thể được tính từ giá trị của các điểm A, B, C và D sử dụng công thức D - B - C + A. Ta nhìn các hình dưới đây để dễ hiểu hơn:
Các bước tính toán tổng số pixel
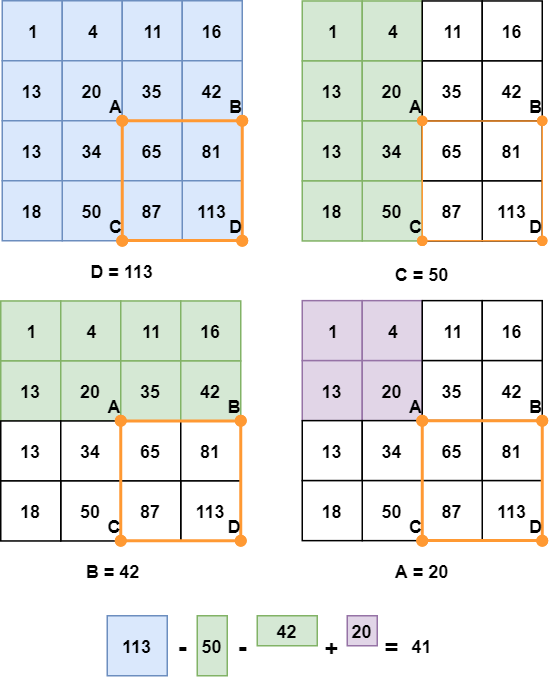
Bạn sẽ nhận thấy rằng trừ cả B và C có nghĩa là khu vực được xác định với A đã bị trừ hai lần, vì vậy chúng ta cần phải cộng lại nó một lần nữa.
Bây giờ bạn có một cách đơn giản để tính toán sự khác biệt giữa tổng giá trị pixel của hai hình chữ nhật. Điều này là hoàn hảo cho các tính năng Haar-Like!
Nhưng làm thế nào để bạn quyết định tính năng nào trong số những tính năng này và kích thước sử dụng để tìm khuôn mặt trong hình ảnh? Điều này được giải quyết bằng một thuật toán học máy được gọi là tăng cường. Cụ thể, bạn sẽ tìm hiểu về AdaBoost, viết tắt của cụm từ Tăng cường thích ứng (Adaptive Boosting).
AdaBoost
Việc thúc đẩy dựa trên câu hỏi sau: “Liệu một nhóm người học yếu có thể tạo ra một người học mạnh duy nhất không?” Người học yếu (hoặc người phân loại yếu) được định nghĩa là người phân loại chỉ tốt hơn một chút so với việc đoán ngẫu nhiên.
Trong tính năng phát hiện khuôn mặt, điều này có nghĩa là người học yếu có thể phân loại một tiểu vùng của hình ảnh thành khuôn mặt hoặc không khuôn mặt chỉ tốt hơn một chút so với đoán ngẫu nhiên. Một người học giỏi về cơ bản tốt hơn trong việc chọn khuôn mặt từ những người không có khuôn mặt.
Sức mạnh của việc tăng cường đến từ việc kết hợp nhiều (hàng nghìn) bộ phân loại yếu thành một bộ phân loại mạnh duy nhất. Trong thuật toán Viola-Jones, mỗi tính năng Haar-Like đại diện cho một người học yếu. Để quyết định loại và kích thước của một tính năng đi vào bộ phân loại cuối cùng, AdaBoost kiểm tra hiệu suất của tất cả các bộ phân loại mà bạn cung cấp cho nó.
Để tính toán hiệu suất của bộ phân loại, bạn đánh giá nó trên tất cả các tiểu vùng của tất cả các hình ảnh được sử dụng để đào tạo. Một số vùng con sẽ tạo ra phản hồi mạnh mẽ trong trình phân loại. Những thứ đó sẽ được phân loại là mặt tích cực, có nghĩa là bộ phân loại nghĩ rằng nó có chứa một khuôn mặt người.
Theo ý kiến của các nhà phân loại, các tiểu vùng không tạo ra phản hồi mạnh sẽ không chứa khuôn mặt người. Chúng sẽ được phân loại là âm bản.
Các bộ phân loại hoạt động tốt có tầm quan trọng hoặc trọng số cao hơn. Kết quả cuối cùng là một bộ phân loại mạnh, còn được gọi là bộ phân loại tăng cường, chứa các bộ phân loại yếu hoạt động tốt nhất.
Thuật toán được gọi là thích ứng bởi vì, khi quá trình đào tạo tiến triển, nó sẽ nhấn mạnh hơn vào những hình ảnh đã được phân loại không chính xác. Các bộ phân loại yếu hoạt động tốt hơn trên các ví dụ cứng này có trọng số mạnh hơn các bộ phân loại khác.
Hãy xem một ví dụ:
Các vòng tròn màu xanh và màu cam là các mẫu thuộc các loại khác nhau.
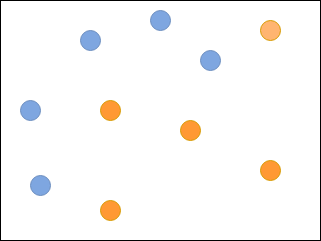
Hãy tưởng tượng rằng bạn phải phân loại các vòng tròn màu xanh lam và màu da cam trong hình ảnh sau đây bằng cách sử dụng một tập hợp các bộ phân loại yếu:
Bộ phân loại yếu đầu tiên phân loại một số vòng tròn màu xanh lam một cách chính xác.
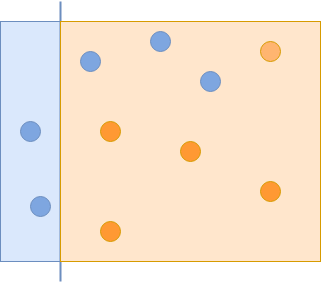
Bộ phân loại đầu tiên bạn sử dụng nắm bắt một số vòng tròn màu xanh lam nhưng bỏ sót những vòng tròn khác. Trong lần lặp tiếp theo, bạn đưa ra tầm quan trọng hơn cho các ví dụ bị bỏ lỡ:
Các mẫu màu xanh bị bỏ sót có tầm quan trọng hơn, được biểu thị bằng kích thước.
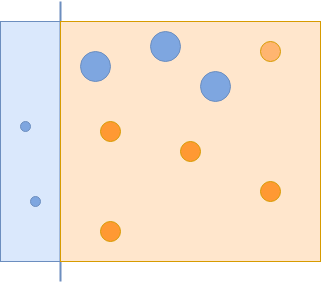
Bộ phân loại thứ hai quản lý để phân loại chính xác các ví dụ đó sẽ có trọng số cao hơn. Hãy nhớ rằng, nếu bộ phân loại yếu hoạt động tốt hơn, nó sẽ có trọng số cao hơn và do đó cơ hội được đưa vào bộ phân loại mạnh cuối cùng cao hơn:
Bộ phân loại thứ hai chụp các vòng tròn màu xanh lam lớn hơn.
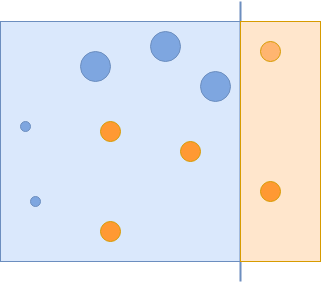
Bây giờ bạn đã quản lý để chụp tất cả các vòng tròn màu xanh lam, nhưng chụp không chính xác một số vòng tròn màu cam. Các vòng tròn màu cam được phân loại không chính xác này có tầm quan trọng hơn trong lần lặp tiếp theo:
Các vòng tròn màu cam bị phân loại sai có tầm quan trọng hơn, và các vòng tròn khác bị giảm đi.
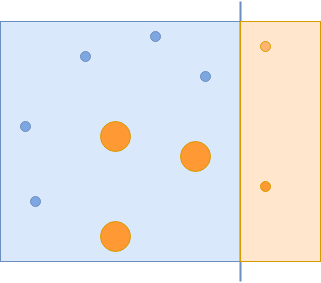
Bộ phân loại cuối cùng quản lý để nắm bắt các vòng tròn màu cam đó một cách chính xác:
Bộ phân loại thứ ba chụp các vòng tròn màu cam còn lại.
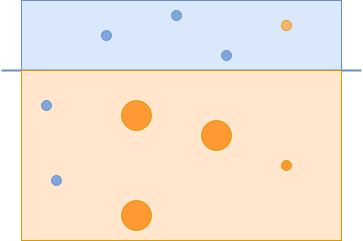
Để tạo một bộ phân loại mạnh, bạn kết hợp cả ba bộ phân loại để phân loại chính xác tất cả các ví dụ:
Bộ phân loại mạnh, cuối cùng kết hợp cả ba bộ phân loại yếu.
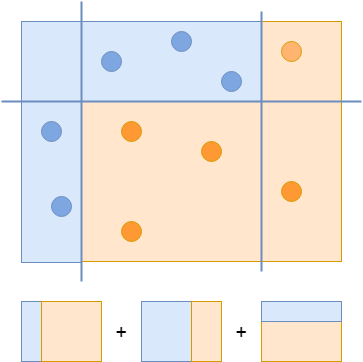
Sử dụng một biến thể của quy trình này, Viola và Jones đã đánh giá hàng trăm nghìn bộ phân loại chuyên tìm kiếm khuôn mặt trong hình ảnh. Nhưng sẽ rất tốn kém về mặt tính toán nếu chạy tất cả các bộ phân loại này trên mọi vùng trong mọi hình ảnh, vì vậy họ đã tạo ra một thứ gọi là tầng bộ phân loại (classifier cascade).
Bộ phân loại xếp tầng (Cascading Classifiers)
Định nghĩa của một tầng là một loạt các tầng nối tiếp nhau. Một khái niệm tương tự được sử dụng trong khoa học máy tính để giải quyết một vấn đề phức tạp với các đơn vị đơn giản. Vấn đề ở đây là giảm số lần tính toán cho mỗi hình ảnh.
Để giải quyết vấn đề này, Viola và Jones đã biến bộ phân loại mạnh của họ (bao gồm hàng nghìn bộ phân loại yếu) thành một tầng trong đó mỗi bộ phân loại yếu đại diện cho một giai đoạn. Công việc của cascade là nhanh chóng loại bỏ những khuôn mặt không phải và tránh lãng phí thời gian quý báu và tính toán.
Khi một tiểu vùng hình ảnh đi vào tầng, nó được đánh giá bởi giai đoạn đầu tiên. Nếu giai đoạn đó đánh giá tiểu vùng là tích cực, có nghĩa là nó cho rằng đó là một khuôn mặt, thì đầu ra của giai đoạn đó là có thể.
Nếu một tiểu vùng nhận được có thể, nó sẽ được gửi đến giai đoạn tiếp theo của thác. Nếu điều đó đưa ra đánh giá tích cực, thì đó có thể là cái khác và hình ảnh được gửi đến giai đoạn thứ ba:
Một bộ phân loại yếu trong một tầng
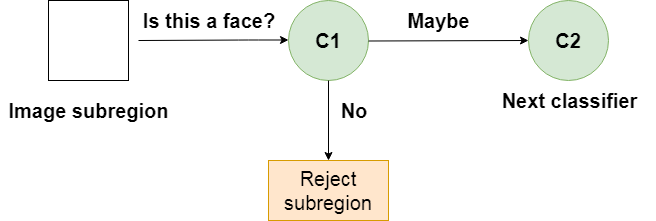
Quá trình này được lặp lại cho đến khi hình ảnh đi qua tất cả các giai đoạn của tầng. Nếu tất cả các bộ phân loại chấp thuận hình ảnh, thì hình ảnh cuối cùng được phân loại thành khuôn mặt người và được hiển thị cho người dùng như một sự phát hiện.
Tuy nhiên, nếu giai đoạn đầu tiên đưa ra đánh giá tiêu cực, thì hình ảnh đó ngay lập tức bị loại bỏ vì không chứa khuôn mặt người. Nếu nó vượt qua giai đoạn đầu tiên nhưng không thành công giai đoạn thứ hai, nó cũng bị loại bỏ. Về cơ bản, hình ảnh có thể bị loại bỏ ở bất kỳ giai đoạn nào của trình phân loại:
Một loạt các bộ phân loại _n_ để nhận diện khuôn mặt
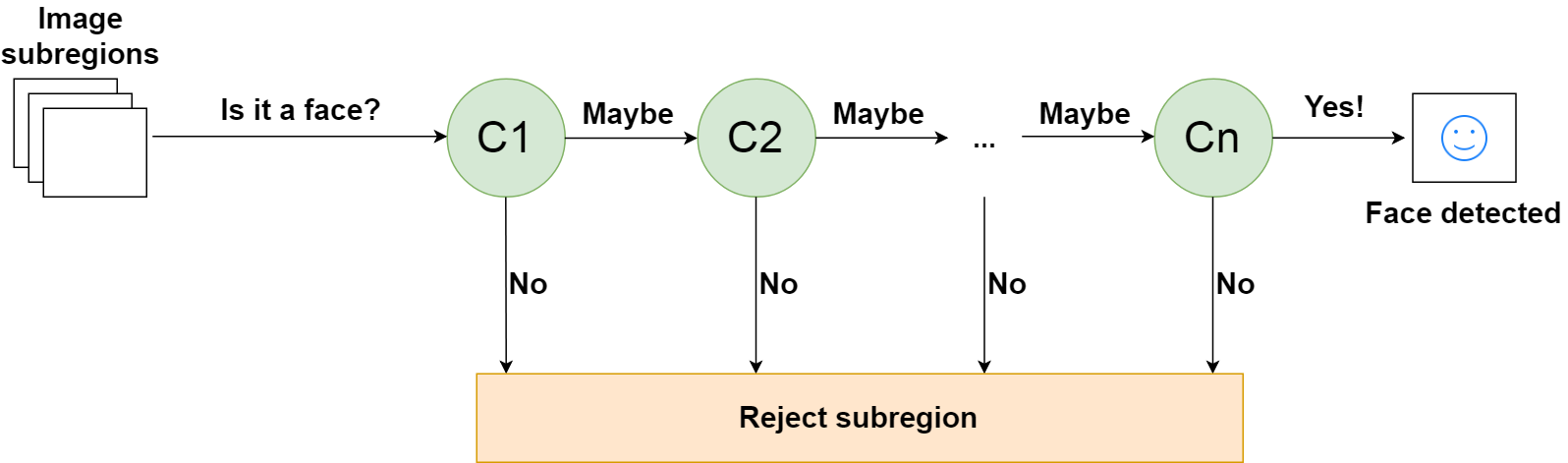
Điều này được thiết kế để các mặt không phải bị loại bỏ rất nhanh chóng, giúp tiết kiệm rất nhiều thời gian và tài nguyên tính toán. Vì mọi bộ phân loại đại diện cho một đặc điểm của khuôn mặt người, một phát hiện tích cực về cơ bản cho biết, "Có, tiểu vùng này chứa tất cả các đặc điểm của khuôn mặt người." Nhưng ngay khi thiếu một tính năng, nó sẽ từ chối toàn bộ tiểu vùng.
Để thực hiện điều này một cách hiệu quả, điều quan trọng là phải sớm đưa các bộ phân loại hoạt động tốt nhất của bạn vào tầng. Trong thuật toán Viola-Jones, bộ phân loại mắt và sống mũi là ví dụ về bộ phân loại yếu hoạt động tốt nhất.
Bây giờ bạn đã hiểu cách hoạt động của thuật toán, đã đến lúc sử dụng nó để phát hiện khuôn mặt với Python.
Sử dụng Bộ phân loại Viola-Jones
Việc đào tạo một bộ phân loại Viola-Jones từ đầu có thể mất nhiều thời gian. May mắn thay, bộ phân loại Viola-Jones được đào tạo trước đã xuất hiện sẵn sàng với OpenCV! Bạn sẽ sử dụng điều này để xem thuật toán đang hoạt động.
Đầu tiên, hãy tìm và tải xuống một hình ảnh mà bạn muốn quét để tìm sự hiện diện của khuôn mặt người. Đây là một ví dụ:
Kho ảnh mẫu để nhận diện khuôn mặt (Nguồn ảnh)

Import OpenCV và tải hình ảnh vào bộ nhớ:
import cv2 as cv
# Đọc ảnh từ máy tính của bạn
original_image = cv.imread('path/to/your-image.jpg')
# Chuyển đổi màu ảnh thành dạng thang độ xám với Viola-Jones
grayscale_image = cv.cvtColor(original_image, cv.COLOR_BGR2GRAY)
Tiếp theo, bạn cần tải trình phân loại Viola-Jones. Nếu bạn đã cài đặt OpenCV từ nguồn, nó sẽ nằm trong thư mục mà bạn đã cài đặt thư viện OpenCV.
Tùy thuộc vào phiên bản, đường dẫn chính xác có thể khác nhau, nhưng tên thư mục sẽ là haarcascades, và nó sẽ chứa nhiều tệp. File bạn cần được gọi haarcascade_frontalface_alt.xml.
Nếu vì lý do nào đó, việc cài đặt OpenCV của bạn không nhận được bộ phân loại được đào tạo trước, bạn có thể tải nó từ repo OpenCV GitHub:
# Tải (load) bộ phân loại và tạo một đối tượng tầng cho nhận diện khuôn mặt
face_cascade = cv.CascadeClassifier('path/to/haarcascade_frontalface_alt.xml')
Đối tượng face_cascade có một phương thức là detectMultiScale(), phương thức này nhận một hình ảnh làm đối số và chạy tầng phân loại trên hình ảnh. Thuật ngữ MultiScale chỉ ra rằng thuật toán xem xét các vùng con của hình ảnh theo nhiều tỷ lệ, để phát hiện các khuôn mặt có kích thước khác nhau:
detected_faces = face_cascade.detectMultiScale(grayscale_image)
Bây giờ biến detected_faces chứa tất cả các phát hiện cho hình ảnh mục tiêu. Để hình dung các phát hiện, bạn cần lặp lại tất cả các phát hiện và vẽ các hình chữ nhật trên các mặt được phát hiện.
rectangle() của OpenCV vẽ các hình chữ nhật trên các hình ảnh và nó cần biết tọa độ pixel của góc trên bên trái và góc dưới bên phải. Các tọa độ cho biết hàng và cột pixel trong hình ảnh.
May mắn thay, các phát hiện được lưu dưới dạng tọa độ pixel. Mỗi phát hiện được xác định bởi tọa độ góc trên cùng bên trái và chiều rộng và chiều cao của hình chữ nhật bao gồm khuôn mặt được phát hiện.
Thêm chiều rộng vào hàng và chiều cao vào cột sẽ cung cấp cho bạn góc dưới cùng bên phải của hình ảnh:
for (column, row, width, height) in detected_faces:
cv.rectangle(
original_image,
(column, row),
(column + width, row + height),
(0, 255, 0),
2
)
rectangle() chấp nhận các đối số sau:
- Ảnh gốc
- Tọa độ của điểm trên cùng bên trái của phát hiện
- Tọa độ của điểm dưới cùng bên phải của phát hiện
- Màu của hình chữ nhật (một bộ xác định số lượng màu đỏ, xanh lục và xanh lam (
0-255)) - Độ dày của các đường hình chữ nhật
Cuối cùng, bạn cần hiển thị hình ảnh:
cv.imshow('Image', original_image)
cv.waitKey(0)
cv.destroyAllWindows()
imshow() hiển thị hình ảnh. waitKey() chờ một lần gõ phím. Nếu không, imshow() sẽ hiển thị hình ảnh và ngay lập tức đóng cửa sổ. Truyền 0 khi đối số yêu cầu nó chờ vô thời hạn. Cuối cùng, destroyAllWindows() đóng cửa sổ khi bạn nhấn một phím.
Đây là kết quả:
Hình ảnh gốc với các phát hiện

Như vậy, đến đây thì bạn đã có một công cụ dò tìm khuôn mặt sẵn sàng sử dụng bằng Python.
Nếu bạn thực sự muốn tự đào tạo bộ phân loại, thì scikit-image cung cấp một hướng dẫn có mã kèm theo trên trang web của họ.
Đọc thêm
Thuật toán Viola-Jones là một thành tựu đáng kinh ngạc. Mặc dù nó vẫn hoạt động tuyệt vời cho nhiều trường hợp sử dụng, nhưng nó đã gần 20 năm tuổi. Các thuật toán khác tồn tại và chúng sử dụng các tính năng khác nhau
Một ví dụ sử dụng máy vectơ hỗ trợ (Support Vector Machines - SVM) và các tính năng được gọi là biểu đồ của gradient có định hướng (Histograms of Oriented Gradients - HOG). Có thể tìm thấy một ví dụ trong Sổ tay Khoa học Dữ liệu Python.
Hầu hết các phương pháp hiện đại để phát hiện và nhận dạng khuôn mặt đều sử dụng học sâu (Deep Learning), chúng tôi sẽ đề cập đến vấn đề này trong một bài viết tiếp theo.
Đối với nghiên cứu thị giác máy tính hiện đại, hãy xem các bài báo khoa học gần đây về Nhận dạng Mẫu và Thị giác Máy tính của arXiv.
Nếu bạn quan tâm đến học máy nhưng muốn chuyển sang một thứ khác ngoài thị giác máy tính, hãy xem Phân loại văn bản thực tế với Python và Keras.
Kết luận
Chúc mừng bạn! Bây giờ bạn đã biết cách tìm thấy khuôn mặt trong hình ảnh.
Trong bài hướng dẫn này, bạn đã học cách biểu diễn các vùng trong một hình ảnh với các tính năng Haar-Like. Các tính năng này có thể được tính toán rất nhanh chóng bằng cách sử dụng hình ảnh tích phân.
Bạn đã biết cách AdaBoost tìm thấy các tính năng Haar-Like hoạt động tốt nhất từ hàng nghìn tính năng có sẵn và biến chúng thành một loạt bộ phân loại yếu.
Cuối cùng, bạn đã học được cách tạo một loạt các bộ phân loại yếu có thể phân biệt khuôn mặt và không phải khuôn mặt một cách nhanh chóng và đáng tin cậy.
Các bước này minh họa nhiều yếu tố quan trọng của thị giác máy tính:
- Tìm kiếm các tính năng hữu ích
- Kết hợp chúng để giải quyết các vấn đề phức tạp
- Cân bằng giữa hiệu suất và quản lý tài nguyên tính toán
Những ý tưởng này được áp dụng cho việc phát hiện đối tượng nói chung và sẽ giúp bạn giải quyết nhiều thách thức trong thế giới thực. Good luck!