Giải thuật và lập trình: §8.1. Sắp xếp (SORTING) - Phần 1
Giải phóng thời gian, khai phóng năng lực
BÀI TOÁN SẮP XẾP
Sắp xếp là quá trình bố trí lại các phần tử của một tập đối tượng nào đó theo một thứ tự nhất định. Chẳng hạn như thứ tự tăng dần (hay giảm dần) đối với một dãy số, thứ tự từ điển đối với các từ v.v… Yêu cầu về sắp xếp thường xuyên xuất hiện trong các ứng dụng Tin học với các mục đích khác nhau: sắp xếp dữ liệu trong máy tính để tìm kiếm cho thuận lợi, sắp xếp các kết quả xử lý để in ra trên bảng biểu v.v…
Nói chung, dữ liệu có thể xuất hiện dưới nhiều dạng khác nhau, nhưng ở đây ta quy ước: Một tập các đối tượng cần sắp xếp là tập các bản ghi (records), mỗi bản ghi bao gồm một số trường (fields) khác nhau. Nhưng không phải toàn bộ các trường dữ liệu trong bản ghi đều được xem xét đến trong quá trình sắp xếp mà chỉ là một trường nào đó (hay một vài trường nào đó) được chú ý tới thôi. Trường như vậy ta gọi là khoá (key). Sắp xếp sẽ được tiến hành dựa vào giá trị của khoá này.
Ví dụ: Hồ sơ tuyển sinh của một trường Đại học là một danh sách thí sinh, mỗi thí sinh có tên, số báo danh, điểm thi. Khi muốn liệt kê danh sách những thí sinh trúng tuyển tức là phải sắp xếp các thí sinh theo thứ tự từ điểm cao nhất tới điểm thấp nhất. Ở đây khoá sắp xếp chính là điểm thi.
|
STT |
SBD |
Họ và tên |
Điểm thi |
|---|---|---|---|
|
1 |
A100 |
Nguyễn Văn A |
20 |
|
2 |
B200 |
Trần Thị B |
25 |
|
3 |
X150 |
Phạm Văn C |
18 |
|
4 |
G180 |
Đỗ Thị D |
21 |
Khi sắp xếp, các bản ghi trong bảng sẽ được đặt lại vào các vị trí sao cho giá trị khoá tương ứng với chúng có đúng thứ tự đã ấn định. Vì kích thước của toàn bản ghi có thể rất lớn, nên nếu việc sắp xếp thực hiện trực tiếp trên các bản ghi sẽ đòi hỏi sự chuyển đổi vị trí của các bản ghi, kéo theo việc thường xuyên phải di chuyển, copy những vùng nhớ lớn, gây ra những tổn phí thời gian khá nhiều. Thường người ta khắc phục tình trạng này bằng cách xây dựng một bảng khoá: Mỗi bản ghi trong bảng ban đầu sẽ tương ứng với một bản ghi trong bảng khoá. Bảng khoá cũng gồm các bản ghi nhưng mỗi bản ghi chỉ gồm có hai trường:
- Trường thứ nhất chứa khoá.
- Trường thứ hai chứa liên kết tới một bản ghi trong bảng ban đầu, tức là chứa một thông tin đủ để biết bản ghi tương ứng với nó trong bảng ban đầu là bản ghi nào.
Sau đó, việc sắp xếp được thực hiện trực tiếp trên bảng khoá, trong quá trình sắp xếp, bảng chính không hề bị ảnh hưởng gì, việc truy cập vào một bản ghi nào đó của bảng chính vẫn có thể thực hiện được bằng cách dựa vào trường liên kết của bản ghi tương ứng thuộc bảng khoá.
Như ở ví dụ trên, ta có thể xây dựng bảng khoá gồm 2 trường, trường khoá chứa điểm và trường liên kết chứa số thứ tự của người có điểm tương ứng trong bảng ban đầu:
|
Điểm thi |
STT |
|---|---|
|
20 |
1 |
|
25 |
2 |
|
18 |
3 |
|
21 |
4 |
Sau khi sắp xếp theo trật tự điểm cao nhất tới điểm thấp nhất, bảng khoá sẽ trở thành:
|
Điểm thi |
STT |
|---|---|
|
25 |
2 |
|
21 |
4 |
|
20 |
1 |
|
18 |
3 |
Dựa vào bảng khoá, ta có thể biết được rằng người có điểm cao nhất là người mang số thứ tự 2, tiếp theo là người mang số thứ tự 4, tiếp nữa là người mang số thứ tự 1, và cuối cùng là người mang số thứ tự 3, còn muốn liệt kê danh sách đầy đủ thì ta chỉ việc đối chiếu với bảng ban đầu và liệt kê theo thứ tự 2, 4, 1, 3.
Có thể còn cải tiến tốt hơn dựa vào nhận xét sau: Trong bảng khoá, nội dung của trường khoá hoàn toàn có thể suy ra được từ trường liên kết bằng cách: Dựa vào trường liên kết, tìm tới bản ghi tương ứng trong bảng chính rồi truy xuất trường khoá trong bảng chính. Như ví dụ trên thì người mang số thứ tự 1 chắc chắn sẽ phải có điểm thi là 20, còn người mang số thứ tự 3 thì chắc chắn phải có điểm thi là 18. Vậy thì bảng khoá có thể loại bỏ đi trường khoá mà chỉ giữ lại trường liên kết. Trong trường hợp các phần tử trong bảng ban đầu được đánh số từ 1 tới n và trường liên kết chính là số thứ tự của bản ghi trong bảng ban đầu như ở ví dụ trên, người ta gọi kỹ thuật này là kỹ thuật sắp xếp bằng chỉ số: Bảng ban đầu không hề bị ảnh hưởng gì cả, việc sắp xếp chỉ đơn thuần là đánh lại chỉ số cho các bản ghi theo thứ tự sắp xếp. Cụ thể hơn:
Nếu r[1], r[2], …, r[n] là các bản ghi cần sắp xếp theo một thứ tự nhất định thì việc sắp xếp bằng chỉ số tức là xây dựng một dãy Index[1], Index[2], …, Index[n] mà ở đây:
Index[j] = Chỉ số của bản ghi sẽ đứng thứ j khi sắp thứ tự (Bản ghi r[index[j]] sẽ phải đứng sau j - 1 bản ghi khác khi sắp xếp)
Do khoá có vai trò đặc biệt như vậy nên sau này, khi trình bày các giải thuật, ta sẽ coi khoá như đại diện cho các bản ghi và để cho đơn giản, ta chỉ nói tới giá trị của khoá mà thôi. Các thao tác trong kỹ thuật sắp xếp lẽ ra là tác động lên toàn bản ghi giờ đây chỉ làm trên khoá.
Còn việc cài đặt các phương pháp sắp xếp trên danh sách các bản ghi và kỹ thuật sắp xếp bằng chỉ số, ta coi như bài tập.
Bài toán sắp xếp giờ đây có thể phát biểu như sau:
Xét quan hệ thứ tự toàn phần "nhỏ hơn hoặc bằng" ký hiệu "≤" trên một tập hợp S, là quan hệ hai ngôi thoả mãn bốn tính chất:
Với ∀a, b, c ∈ S
Tính phổ biến: Hoặc là a ≤ b, hoặc b ≤ a; Tính phản xạ: a ≤ a.
Tính phản đối xứng: Nếu a ≤ b và b ≤ a thì bắt buộc a = b. Tính bắc cầu: Nếu có a ≤ b và b ≤ c thì a ≤ c.
Trong trường hợp a ≤ b và a ≠ b, ta dùng ký hiệu "<" cho gọn.
Cho một dãy gồm n khoá. Giữa hai khoá bất kỳ có quan hệ thứ tự toàn phần "≤". Xếp lại dãy các khoá đó để được dãy khoá thoả mãn k1 ≤ k2 ≤ …≤ kn.
Giả sử cấu trúc dữ liệu cho dãy khoá được mô tả như sau:
const
n = …; {Số khoá trong dãy khoá, có thể khai dưới dạng biến số nguyên để tuỳ biến hơn}
type
TKey = …; {Kiểu dữ liệu một khoá}
TArray = array[1..n] of TKey;
var
k: TArray; {Dãy khoá}
Thì những thuật toán sắp xếp dưới đây được viết dưới dạng thủ tục sắp xếp dãy khoá k, kiểu chỉ số đánh cho từng khoá trong dãy có thể coi là số nguyên Integer.
THUẬT TOÁN SẮP XẾP KIỂU CHỌN (SELECTIONSORT)
Một trong những thuật toán sắp xếp đơn giản nhất là phương pháp sắp xếp kiểu chọn. Ý tưởng cơ bản của cách sắp xếp này là:
Ở lượt thứ nhất, ta chọn trong dãy khoá k1, k2, …, kn ra khoá nhỏ nhất (khoá ≤ mọi khoá khác) và đổi giá trị của nó với k1, khi đó giá trị khoá k1 trở thành giá trị khoá nhỏ nhất.
Ở lượt thứ hai, ta chọn trong dãy khoá k2, …, kn ra khoá nhỏ nhất và đổi giá trị của nó với k2.
…
Ở lượt thứ i, ta chọn trong dãy khoá ki, ki+1, …, kn ra khoá nhỏ nhất và đổi giá trị của nó với ki.
…
Làm tới lượt thứ n - 1, chọn trong hai khoá kn-1, kn ra khoá nhỏ nhất và đổi giá trị của nó với kn-1.
procedure SelectionSort;
var
i, j, jmin: Integer;
begin
for i := 1 to n - 1 do {Làm n - 1 lượt}
begin
{Chọn trong số các khoá từ ki tới kn ra khoá kjmin nhỏ nhất}
jmin := i;
for j := i + 1 to n do
if kj < kjmin then jmin := j;
if jmin ≠ i then
<Đảo giá trị của kjmin cho ki>
end;
end;
Đối với phương pháp kiểu lựa chọn, ta có thể coi phép so sánh (kj < kjmin) là phép toán tích cực để đánh giá hiệu suất thuật toán về mặt thời gian. Ở lượt thứ i, để chọn ra khoá nhỏ nhất bao giờ cũng cần n - i phép so sánh, số lượng phép so sánh này không hề phụ thuộc gì vào tình trạng ban đầu của dãy khoá cả. Từ đó suy ra tổng số phép so sánh sẽ phải thực hiện là:
(n - 1) + (n - 2) + … + 1 = n * (n - 1) / 2
Vậy thuật toán sắp xếp kiểu chọn có cấp là O(n2).
THUẬT TOÁN SẮP XẾP NỔI BỌT (BUBBLESORT)
Trong thuật toán sắp xếp nổi bọt, dãy các khoá sẽ được duyệt từ cuối dãy lên đầu dãy (từ kn về k1), nếu gặp hai khoá kế cận bị ngược thứ tự thì đổi chỗ của chúng cho nhau. Sau lần duyệt như vậy, phần tử nhỏ nhất trong dãy khoá sẽ được chuyển về vị trí đầu tiên và vấn đề trở thành sắp xếp dãy khoá từ k2 tới kn:
procedure BubbleSort;
var
i, j: Integer;
begin
for i := 2 to n do
for j := n downto i do {Duyệt từ cuối dãy lên, làm nổi khoá nhỏ nhất trong số ki-1, …,kn về vị trí i-1}
if kj < kj-1 then
<Đảo giá trị kj và kj-1>
end;
Đối với thuật toán sắp xếp nổi bọt, ta có thể coi phép toán tích cực là phép so sánh kj < kj-1.
Và số lần thực hiện phép so sánh này là:
(n - 1) + (n - 2) + … + 1 = n * (n - 1) / 2
Vậy, thuật toán sắp xếp nổi bọt cũng có cấp là O(n2). Bất kể tình trạng dữ liệu vào như thế nào.
THUẬT TOÁN SẮP XẾP KIỂU CHÈN (INSERTIONSORT)
Xét dãy khoá k1, k2, …, kn. Ta thấy dãy con chỉ gồm mỗi một khoá là k1 có thể coi là đã sắp xếp rồi. Xét thêm k2, ta so sánh nó với k1, nếu thấy k2 < k1 thì chèn nó vào trước k1. Đối với k3, ta lại xét dãy chỉ gồm 2 khoá k1, k2 đã sắp xếp và tìm cách chèn k3 vào dãy khoá đó để được thứ tự sắp xếp. Một cách tổng quát, ta sẽ sắp xếp dãy k1, k2, …, ki trong điều kiện dãy k1, k2, …, ki-1 đã sắp xếp rồi bằng cách chèn ki vào dãy đó tại vị trí đúng khi sắp xếp.
procedure InsertionSort;
var
i, j: Integer;
tmp: TKey; {Biến giữ lại giá trị khoá chèn}
begin
for i := 2 to n do {Chèn giá trị ki vào dãy k1,…, ki-1 để toàn đoạn k1, k2,…, ki trở thành đã sắp xếp}
begin
tmp := ki; {Giữ lại giá trị ki}
j := i - 1;
while (j > 0) and (tmp < kj) do {So sánh giá trị cần chèn với lần lượt các khoá kj (i-1≥j≥0)}
begin
kj+1 := kj; {Đẩy lùi giá trị kj về phía sau một vị trí, tạo ra "khoảng trống" tại vị trí j}
j := j - 1;
end;
kj+1 := tmp; {Đưa giá trị chèn vào "khoảng trống" mới tạo ra}
end;
end;
Đối với thuật toán sắp xếp kiểu chèn, thì chi phí thời gian thực hiện thuật toán phụ thuộc vào tình trạng dãy khoá ban đầu. Nếu coi phép toán tích cực ở đây là phép so sánh tmp < kj thì: Trường hợp tốt nhất ứng với dãy khoá đã sắp xếp rồi, mỗi lượt chỉ cần 1 phép so sánh, và như vậy tổng số phép so sánh được thực hiện là n - 1.
Trường hợp tồi tệ nhất ứng với dãy khoá đã có thứ tự ngược với thứ tự cần sắp thì ở lượt thứ i, cần có i - 1 phép so sánh và tổng số phép so sánh là:
(n - 1) + (n - 2) + … + 1 = n * (n - 1) / 2.
Trường hợp các giá trị khoá xuất hiện một cách ngẫu nhiên, ta có thể coi xác suất xuất hiện mỗi khoá là đồng khả năng, thì có thể coi ở lượt thứ i, thuật toán cần trung bình i / 2 phép so sánh và tổng số phép so sánh là:
(1 / 2) + (2 / 2) + … + (n / 2) = (n + 1) * n / 4.
Nhìn về kết quả đánh giá, ta có thể thấy rằng thuật toán sắp xếp kiểu chèn tỏ ra tốt hơn so với thuật toán sắp xếp chọn và sắp xếp nổi bọt. Tuy nhiên, chi phí thời gian thực hiện của thuật toán sắp xếp kiểu chèn vẫn còn khá lớn. Và xét trên phương diện tính toán lý thuyết thì cấp của thuật toán sắp xếp kiểu chèn vẫn là O(n2).
Có thể cải tiến thuật toán sắp xếp chèn nhờ nhận xét: Khi dãy khoá k1, k2, …, ki-1 đã được sắp xếp thì việc tìm vị trí chèn có thể làm bằng thuật toán tìm kiếm nhị phân và kỹ thuật chèn có thể làm bằng các lệnh dịch chuyển vùng nhớ cho nhanh. Tuy nhiên điều đó cũng không làm tốt hơn cấp độ phức tạp của thuật toán bởi trong trường hợp xấu nhất, ta phải mất n - 1 lần chèn và lần chèn thứ i ta phải dịch lùi i khoá để tạo ra khoảng trống trước khi đẩy giá trị khoá chèn vào chỗ trống đó.
procedure InsertionSortwithBinarySearching;
var
i, inf, sup, median: Integer;
tmp: TKey;
begin
for i := 2 to n do begin
tmp := ki; {Giữ lại giá trị ki}
inf := 1;
sup := i - 1; {Tìm chỗ chèn giá trị tmp vào đoạn từ kinf tới ksup+1}
repeat {Sau mỗi vòng lặp này thì đoạn tìm bị co lại một nửa}
median := (inf + sup) div 2; {Xét chỉ số nằm giữa chỉ số inf và chỉ số sup}
if tmp < k[median] then sup := median - 1 else inf := median + 1;
until inf > sup; {Kết thúc vòng lặp thì inf = sup + 1 chính là vị trí chèn}
<Dịch các phần tử từ kinf tới ki-1 lùi sau một vị trí>
kinf := tmp; {Đưa giá trị tmp vào "khoảng trống" mới tạo ra}
end;
end;
Dưới đây là đoạn code viết bằng C sử dụng thuật toán sắp xếp chèn:
#include <stdio.h> #include <math.h> /* Thuật toán sắp xếp chèn */ void thuatToanSapXepChen(int arr[], int size){ int i, key, j; for (i = 1; i < size; i++){ key = arr[i]; j = i-1; /* Di chuyển các phần tử có giá trị lớn hơn giá trị key về sau một vị trí so với vị trí ban đầu của nó */ while (j >= 0 && arr[j] > key){ arr[j+1] = arr[j]; j = j-1; } arr[j+1] = key; } } /* Hàm xuất mảng */ void printArray(int arr[], int size){ int i; for (i=0; i < size; i++) printf("%d ", arr[i]); printf("\n"); } int main(){ int arr[] = {12, 11, 13, 5, 6}; int size = sizeof(arr)/sizeof(arr[0]); thuatToanSapXepChen(arr, size); printf("Sau khi sap xep tang dan theo phuong phap chen, ta duoc:\n"); printArray(arr, size); return 0; }
SHELLSORT
Nhược điểm của thuật toán sắp xếp kiểu chèn thể hiện khi mà ta luôn phải chèn một khóa vào vị trí gần đầu dãy. Trong trường hợp đó, người ta sử dụng phương pháp ShellSort.
Xét dãy khoá: k1, k2, …, kn. Với một số nguyên dương h: 1 ≤ h ≤ n, ta có thể chia dãy đó thành h dãy con:
Dãy con 1: k1, k1+h, k1 + 2h, …
Dãy con 2: k2, k2+h, k2 + 2h, …
…
Dãy con h: kh, k2h, k3h, …
Ví dụ như dãy (4, 6, 7, 2, 3, 5, 1, 9, 8); n = 9; h = 3. Có 3 dãy con.

Những dãy con như vậy được gọi là dãy con xếp theo độ dài bước h. Tư tưởng của thuật toán ShellSort là: Với một bước h, áp dụng thuật toán sắp xếp kiểu chèn từng dãy con độc lập để làm mịn dần dãy khoá chính. Rồi lại làm tương tự đối với bước h div 2 … cho tới khi h = 1 thì ta được dãy khoá sắp xếp.
Như ở ví dụ trên, nếu dùng thuật toán sắp xếp kiểu chèn thì khi gặp khoá k7 = 1, là khoá nhỏ nhất trong dãy khoá, nó phải chèn vào vị trí 1, tức là phải thao tác trên 6 khoá đứng trước nó. Nhưng nếu coi 1 là khoá của dãy con 1 thì nó chỉ cần chèn vào trước 2 khoá trong dãy con đó mà thôi. Đây chính là nguyên nhân ShellSort hiệu quả hơn sắp xếp chèn: Khoá nhỏ được nhanh chóng đưa về gần vị trí đúng của nó.
procedure ShellSort;
var
i, j, h: Integer;
tmp: TKey;
begin
h := n div 2;
while h <> 0 do {Làm mịn dãy với độ dài bước h}
begin
for i := h + 1 to n do
begin {Sắp xếp chèn trên dãy con ai-h, ai, ai+h, ai+2h, …}
tmp := ki;
j := i - h;
while (j > 0) and (kj > tmp) do begin
kj+h := kj;
j := j - h;
end;
kj+h := tmp;
end;
h := h div 2;
end;
end;
THUẬT TOÁN SẮP XẾP KIỂU PHÂN ĐOẠN (QUICKSORT)
Tư tưởng của QuickSort
QuickSort là một phương pháp sắp xếp tốt nhất, nghĩa là dù dãy khoá thuộc kiểu dữ liệu có thứ tự nào, QuickSort cũng có thể sắp xếp được và không có một thuật toán sắp xếp nào nhanh hơn QuickSort về mặt tốc độ trung bình (theo tôi biết). Người sáng lập ra nó là C.A.R. Hoare đã mạnh dạn đặt tên cho nó là sắp xếp "NHANH".
Ý tưởng chủ đạo của phương pháp có thể tóm tắt như sau: Sắp xếp dãy khoá k1, k2, …, kn thì có thể coi là sắp xếp đoạn từ chỉ số 1 tới chỉ số n trong dãy khoá đó. Để sắp xếp một đoạn trong dãy khoá, nếu đoạn đó có ≤ 1 phần tử thì không cần phải làm gì cả, còn nếu đoạn đó có ít nhất 2 phần tử, ta chọn một khoá ngẫu nhiên nào đó của đoạn làm "chốt" (pivot). Mọi khoá nhỏ hơn khoá chốt được xếp vào vị trí đứng trước chốt, mọi khoá lớn hơn khoá chốt được xếp vào vị trí đứng sau chốt. Sau phép hoán chuyển như vậy thì đoạn đang xét được chia làm hai đoạn khác rỗng mà mọi khoá trong đoạn đầu đều ≤ chốt và mọi khoá trong đoạn sau đều ≥ chốt. Hay nói cách khác: Mỗi khoá trong đoạn đầu đều ≤ mọi khoá trong đoạn sau. Và vấn đề trở thành sắp xếp hai đoạn mới tạo ra (có độ dài ngắn hơn đoạn ban đầu) bằng phương pháp tương tự.
procedure QuickSort;
procedure Partition(L, H: Integer); {Sắp xếp đoạn từ kL, kL+1, …, kH}
var
i, j: Integer;
Pivot: TKey; {Biến lưu giá trị khoá chốt}
begin
if L ³ H then Exit; {Nếu đoạn chỉ có £ 1 phần tử thì không phải làm gì cả} Pivot := kRandom(H-L+1)+L; {Chọn một khoá ngẫu nhiên trong đoạn làm khoá chốt} i := L; j := H; {i := vị trí đầu đoạn; j := vị trí cuối đoạn}
repeat
while ki < Pivot do i := i + 1; {Tìm từ đầu đoạn khoá ³ khoá chốt}
while kj > Pivot do j := j - 1; {Tìm từ cuối đoạn khoá £ khoá chốt}
{Đến đây ta tìm được hai khoá ki và kj mà ki ³ key ³ kj}
if i £ j then begin
if i < j then {Nếu chỉ số i đứng trước chỉ số j thì đảo giá trị hai khoá ki và kj}
<Đảo giá trị ki và kj> {Sau phép đảo này ta có: ki £ key £ kj }
i := i + 1; j := j - 1;
end; until i > j;
Partition(L, j); Partition(i, H); {Sắp xếp hai đoạn con mới tạo ra}
end;
begin
Partition(1, n); end;
Ta thử phân tích xem tại sao đoạn chương trình trên hoạt động đúng: Xét vòng lặp repeat…until trong lần lặp đầu tiên, vòng lặp while thứ nhất chắc chắn sẽ tìm được khoá ki ≥ khoá chốt bởi chắc chắn tồn tại trong đoạn một khoá bằng khóa chốt. Tương tự như vậy, vòng lặp while thứ hai chắc chắn tìm được khoá kj ≤ khoá chốt. Nếu như khoá ki đứng trước khoá kj thì ta đảo giá trị hai khoá, cho i tiến và j lùi. Khi đó ta có nhận xét rằng mọi khoá đứng trước vị trí i sẽ phải ≤ khoá chốt và mọi khoá đứng sau vị trí j sẽ phải ≥ khoá chốt.

Vòng lặp trong của QuickSort
Điều này đảm bảo cho vòng lặp repeat…until tại bước sau, hai vòng lặp while…do bên trong chắc chắn lại tìm được hai khoá ki và kj mà ki ≥ khoá chốt ≥ kj, nếu khoá ki đứng trước khoá kj thì lại đảo giá trị của chúng, cho i tiến về cuối một bước và j lùi về đầu một bước. Vậy thì quá trình hoán chuyển phần tử trong vòng lặp repeat…until sẽ đảm bảo tại mỗi bước:
-
Hai vòng lặp while…do bên trong luôn tìm được hai khoá ki, kj mà ki ≥ khoá chốt ≥ kj. Không có trường hợp hai chỉ số i, j chạy ra ngoài đoạn (luôn luôn có L ≤ i, j ≤ H).
-
Sau mỗi phép hoán chuyển, mọi khoá đứng trước vị trí i luôn ≤ khoá chốt và mọi khoá đứng sau vị trí j luôn ≥ khoá chốt.
Vòng lặp repeat …until sẽ kết thúc khi mà chỉ số i đứng phía sau chỉ số j (như hình dưới đây).

Trạng thái trước khi gọi đệ quy
Theo những nhận xét trên, nếu có một khoá nằm giữa kj và ki thì khoá đó phải đúng bằng khoá chốt và nó đã được đặt ở vị trí đúng của nó, nên có thể bỏ qua khoá này mà chỉ xét hai đoạn ở hai đầu. Công việc còn lại là gọi đệ quy để làm tiếp với đoạn từ kL tới kj và đoạn từ ki tới kH. Hai đoạn này ngắn hơn đoạn đang xét bởi vì L ≤ j < i ≤ H. Vậy thuật toán không bao giờ bị rơi vào quá trình vô hạn mà sẽ dừng và cho kết quả đúng đắn.
Xét về độ phức tạp tính toán:
Trường hợp tồi tệ nhất, là khi chọn khoá chốt, ta chọn phải khoá nhỏ nhất hay lớn nhất trong đoạn, khi đó phép phân đoạn sẽ chia thành một đoạn gồm n - 1 phần tử và đoạn còn lại chỉ có 1 phần tử. Có thể chứng minh trong trường hợp này, thời gian thực hiện giải thuật T(n) = O(n2).
Trường hợp tốt nhất, phép phân đoạn tại mỗi bước sẽ chia được thành hai đoạn bằng nhau. Tức là khi chọn khoá chốt, ta chọn đúng trung vị của dãy khoá. Có thể chứng minh trong trường hợp này, thời gian thực hiện giải thuật T(n) = O(nlog2n).
Trường hợp các khoá được phân bố ngẫu nhiên, thì trung bình thời gian thực hiện giải thuật cũng là T(n) = O(nlog2n).
Việc tính toán chi tiết, đặc biệt là khi xác định T(n) trung bình, phải dùng các công cụ toán phức tạp, ta chỉ công nhận những kết quả trên.
Vài cải tiến của QuickSort
Việc chọn chốt cho phép phân đoạn quyết định hiệu quả của QuickSort, nếu chọn chốt không tốt, rất có thể việc phân đoạn bị suy biến thành trường hợp xấu khiến QuickSort hoạt động chậm và tràn ngăn xếp chương trình con khi gặp phải dây chuyền đệ qui quá dài. Một cải tiến sau có thể khắc phục được hiện tượng tràn ngăn xếp nhưng cũng hết sức chậm trong trường hợp xấu, kỹ thuật này khi đã phân được [L, H] được hai đoạn con [L, j] và [i, H] thì chỉ gọi đệ quy để tiếp tục đối với đoạn ngắn, và lặp lại quá trình phân đoạn đối với đoạn dài.
procedure QuickSort;
procedure Partition(L, H: Integer); {Sắp xếp đoạn từ kL, kL+1, …, kH}
var
i, j: Integer;
begin
repeat
if L ≥ H then Exit;
<Phân đoạn [L, H] được hai đoạn con [L, j] và [i, H]> if <đoạn [L, j] ngắn hơn đoạn [i, H]> then
begin
Partition(L, j); L := i;
end
else
begin
Partition(i, H);
H := j;
end;
until False;
end;
begin
Partition(1, n);
end;
Cải tiến thứ hai đối với QuickSort là quá trình phân đoạn nên chỉ làm đến một mức nào đó, đến khi đoạn đang xét có độ dài ≤ M (M là một số nguyên tự chọn nằm trong khoảng từ 9 tới 25) thì không phân đoạn tiếp mà nên áp dụng thuật toán sắp xếp kiểu chèn.
Cải tiến thứ ba của QuickSort là: Nên lấy trung vị của một dãy con trong đoạn để làm chốt, (trung vị của một dãy n phần tử là phần tử đứng thứ n/2 khi sắp thứ tự). Cách chọn được đánh giá cao nhất là chọn trung vị của ba phần tử đầu, giữa và cuối đoạn.
Cuối cùng, ta có nhận xét: QuickSort là một công cụ sắp xếp mạnh, chỉ có điều khó chịu gặp phải là trường hợp suy biến của QuickSort (quá trình phân đoạn chia thành một dãy rất ngắn và một dãy rất dài). Và điều này trên phương diện lý thuyết là không thể khắc phục được: Ví dụ với n = 10000.
Nếu như chọn chốt là khoá đầu đoạn (Thay dòng chọn khoá chốt bằng Pivot := kL) hay chọn chốt là khoá cuối đoạn (Thay bằng Pivot := kH) thì với dãy sau, chương trình hoạt động rất chậm:
(1, 2, 3, 4, 5, …, 9999, 10000)
Nếu như chọn chốt là khoá giữa đoạn (Thay dòng chọn khoá chốt bằng Pivot := k(L+H) div 2) thì với dãy sau, chương trình cũng rất chậm:
(1, 2, …, 4999, 5000, 5000, 4999, …, 2, 1)
Trong trường hợp chọn chốt là trung vị dãy con hay chọn chốt ngẫu nhiên, thật khó có thể tìm ra một bộ dữ liệu khiến cho QuickSort hoạt động chậm. Nhưng ta cũng cần hiểu rằng với mọi chiến lược chọn chốt, trong 10000! dãy hoán vị của dãy (1, 2, … 10000) thế nào cũng có một dãy làm QuickSort bị suy biến, tuy nhiên trong trường hợp chọn chốt ngẫu nhiên, xác suất xảy ra dãy này quá nhỏ tới mức ta không cần phải tính đến, như vậy khi đã chọn chốt ngẫu nhiên thì ta không cần phải quan tâm tới ngăn xếp đệ quy, không cần quan tâm tới kỹ thuật khử đệ quy và vấn đề suy biến của QuickSort.
Ví dụ áp dụng thuật toán QuickSort dùng lập trình C để sắp xếp tăng:
#include<stdio.h> void hoanVi(int *a, int *b){ int tg = *a; *a = *b; *b = tg; } int phanDoan(int arr[], int low, int high){ int pivot = arr[high]; int left = low; int right = high - 1; while(1){ while(left <= right && arr[left] < pivot){ left++; } while(right >= left && arr[right] > pivot){ right--; } if(left >= right){ break; } hoanVi(&arr[left], &arr[right]); left++; right--; } hoanVi(&arr[left], &arr[high]); //hoán vị hai vị trí return left; } /* Hàm thực hiện giải thuật QuickSort */ void thuatToanQuickSort(int arr[], int low, int high){ if (low < high){ /* pi là chỉ số nơi phần tử này đứng đúng vị trí và là phần từ chia mảng thành hai mảng con trái và phải */ int pi = phanDoan(arr, low, high); // gọi đệ quy và sắp xếp 2 mảng con trái và phải thuatToanQuickSort(arr, low, pi - 1); thuatToanQuickSort(arr, pi + 1, high); } } void inKetQua(int arr[], int size){ int i; for (i=0; i < size; i++) printf("%d ", arr[i]); } int main(){ int arr[] = {3,1,2,4,6,5,9,7,0,8}; int size = sizeof(arr)/sizeof(arr[0]); //Lấy kích thước mảng thuatToanQuickSort(arr, 0, size-1); printf("Sau khi sap xep tang dan theo QuickSort, ta duoc:\n"); inKetQua(arr, size); return 0; }
Ví dụ sau áp dụng thuật toán QuickSort dùng lập trình C để sắp xếp giảm:
#include<stdio.h> void hoanVi(int *a, int *b){ int tg = *a; *a = *b; *b = tg; } int phanDoan(int arr[], int low, int high){ int pivot = arr[high]; int left = low; int right = high - 1; while(1){ while(left <= right && arr[left] > pivot){ left++; } while(right >= left && arr[right] < pivot){ right--; } if(left >= right){ break; } hoanVi(&arr[left], &arr[right]); left++; right--; } hoanVi(&arr[left], &arr[high]); //hoán vị hai vị trí return left; } /* Hàm thực hiện giải thuật QuickSort */ void thuatToanQuickSort(int arr[], int low, int high){ if (low < high){ /* pi là chỉ số nơi phần tử này đứng đúng vị trí và là phần từ chia mảng thành hai mảng con trái và phải */ int pi = phanDoan(arr, low, high); // gọi đệ quy và sắp xếp 2 mảng con trái và phải thuatToanQuickSort(arr, low, pi - 1); thuatToanQuickSort(arr, pi + 1, high); } } void inKetQua(int arr[], int size){ int i; for (i=0; i < size; i++) printf("%d ", arr[i]); } int main(){ int arr[] = {3,1,2,4,6,5,9,7,0,8}; int size = sizeof(arr)/sizeof(arr[0]); //Lấy kích thước mảng thuatToanQuickSort(arr, 0, size-1); printf("Sau khi sap xep tang dan theo QuickSort, ta duoc:\n"); inKetQua(arr, size); return 0; }
THUẬT TOÁN SẮP XẾP KIỂU VUN ĐỐNG (HEAPSORT)
Đống (heap)
Đống là một dạng cây nhị phân hoàn chỉnh đặc biệt mà giá trị lưu tại mọi nút nhánh đều lớn hơn hay bằng giá trị lưu trong hai nút con của nó.
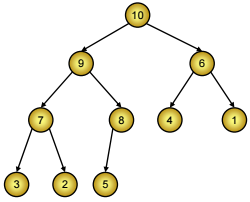
Heap
Vun đống
Trong bài học về cây, ta đã biết một dãy khoá k1, k2, …, kn là biểu diễn của một cây nhị phân hoàn chỉnh mà ki là giá trị lưu trong nút thứ i, nút con của nút thứ i là nút 2i và nút 2i + 1, nút cha của nút thứ j là nút j div 2. Vấn đề đặt ra là sắp lại dãy khoá đã cho để nó biểu diễn một đống.
Vì cây nhị phân chỉ gồm có một nút hiển nhiên là đống, nên để vun một nhánh cây gốc r thành đống, ta có thể coi hai nhánh con của nó (nhánh gốc 2r và 2r + 1) đã là đống rồi và thực hiện thuật toán vun đống từ dưới lên (bottom-up) đối với cây: Gọi h là chiều cao của cây, nút ở mức h (nút lá) đã là gốc một đống, ta vun lên để những nút ở mức h - 1 cũng là gốc của đống, … cứ như vậy cho tới nút ở mức 1 (nút gốc) cũng là gốc của đống.
Thuật toán vun thành đống đối với cây gốc r, hai nhánh con của r đã là đống rồi:
Giả sử ở nút r chứa giá trị V. Từ r, ta cứ đi tới nút con chứa giá trị lớn nhất trong 2 nút con, cho tới khi gặp phải một nút c mà mọi nút con của c đều chứa giá trị £ V (nút lá cũng là trường hợp riêng của điều kiện này). Dọc trên đường đi từ r tới c, ta đẩy giá trị chứa ở nút con lên nút cha và đặt giá trị V vào nút c.
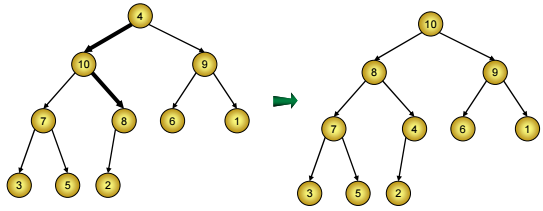
Vun đống
Tư tưởng của HeapSort
Đầu tiên, dãy khoá k1, k2, …, kn được vun từ dưới lên để nó biểu diễn một đống, khi đó khoá k1 tương ứng với nút gốc của đống là khoá lớn nhất, ta đảo giá trị khoá đó cho kn và không tính tới kn nữa (hình dưới). Còn lại dãy khoá k1, k2, …, kn-1 tuy không còn là biểu diễn của một đống nữa nhưng nó lại biểu diễn cây nhị phân hoàn chỉnh mà hai nhánh cây ở nút thứ 2 và nút thứ 3 (hai nút con của nút 1) đã là đống rồi. Vậy chỉ cần vun một lần, ta lại được một đống, đảo giá trị k1 cho kn-1 và tiếp tục cho tới khi đống chỉ còn lại 1 nút.
Ví dụ:
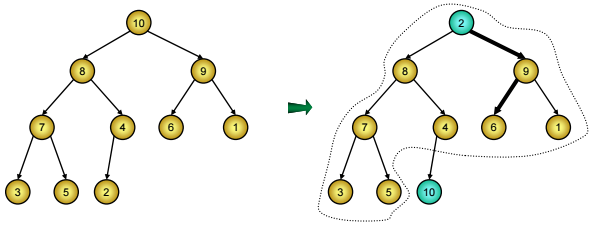
Đảo giá trị k1 cho kn và xét phần còn lại
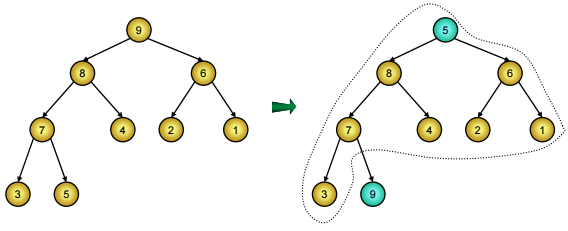
Vun phần còn lại thành đống rồi lại đảo trị k1 cho kn-1
Thuật toán HeapSort có hai thủ tục chính:
- Thủ tục Adjust(root, endnode) vun cây gốc root thành đống trong điều kiện hai cây gốc 2.root và 2.root +1 đã là đống rồi. Các nút từ endnode + 1 tới n đã nằm ở vị trí đúng và không được tính tới nữa.
- Thủ tục HeapSort mô tả lại quá trình vun đống và chọn phần tử theo ý tưởng trên:
procedure HeapSort; var
r, i: Integer;
procedure Adjust(root, endnode: Integer); {Vun cây gốc Root thành đống}
var
c: Integer;
Key: TKey; {Biến lưu giá trị khoá ở nút Root}
begin
Key := kroot;
while root * 2 ≤ endnode do {Chừng nào root chưa phải là lá}
begin
c := Root * 2; {Xét nút con trái của Root, so sánh với giá trị nút con phải, chọn ra nút mang giá trị lớn nhất}
if (c < endnode) and (kc < kc+1) then c := c + 1;
if kc ≤ Key then Break; {Cả hai nút con của Root đều mang giá trị ≤ Key thì dừng ngay}
kroot := kc; root := c; {Chuyển giá trị từ nút con c lên nút cha root và đi xuống xét nút con c}
end;
kroot := Key; {Đặt giá trị Key vào nút root}
end;
begin {Bắt đầu thuật toán HeapSort}
for r := n div 2 downto 1 do Adjust(r, n); {Vun cây từ dưới lên tạo thành đống}
for i := n downto 2 do begin
<Đảo giá trị k1 và ki> {Khoá lớn nhất được chuyển ra cuối dãy}
Adjust(1, i - 1); {Vun phần còn lại thành đống}
end;
end;
Về độ phức tạp của thuật toán, ta đã biết rằng cây nhị phân hoàn chỉnh có n nút thì chiều cao của nó không quá [log2(n + 1)] + 1. Cứ cho là trong trường hợp xấu nhất thủ tục Adjust phải thực hiện tìm đường đi từ nút gốc tới nút lá ở xa nhất thì đường đi tìm được cũng chỉ dài bằng chiều cao của cây và độ phức tạp của một lần gọi Adjust là O(log2n). Từ đó có thể suy ra, trong trường hợp xấu nhất, độ phức tạp của HeapSort cũng chỉ là O(nlog2n). Việc đánh giá thời gian thực hiện trung bình phức tạp hơn, ta chỉ ghi nhận một kết quả đã chứng minh được là độ phức tạp trung bình của HeapSort cũng là O(nlog2n).
Có thể nhận xét thêm là QuickSort đệ quy cần thêm không gian nhớ cho Stack, còn HeapSort ngoài một nút nhớ phụ để thực hiện việc đổi chỗ, nó không cần dùng thêm gì khác. HeapSort tốt hơn QuickSort về phương diện lý thuyết bởi không có trường hợp tồi tệ nào HeapSort có thể mắc phải. Cũng nhờ có HeapSort mà giờ đây khi giải mọi bài toán có chứa mô-đun sắp xếp, ta có thể nói rằng độ phức tạp của thủ tục sắp xếp đó không quá O(nlog2n).
SẮP XẾP BẰNG PHÉP ĐẾM PHÂN PHỐI (DISTRIBUTION COUNTING)
Có một thuật toán sắp xếp đơn giản cho trường hợp đặc biệt: Dãy khoá k1, k2, …, kn là các số nguyên nằm trong khoảng từ 0 tới M (TKey = 0..M).
Ta dựng dãy c0, c1, …, cM các biến đếm, ở đây cV là số lần xuất hiện giá trị V trong dãy khoá:
for V := 0 to M do cV := 0; {Khởi tạo dãy biến đếm}
for i := 1 to n do cki := cki + 1;
Ví dụ với dãy khoá: 1, 2, 2, 3, 0, 0, 1, 1, 3, 3 (n = 10, M = 3), sau bước đếm ta có:c0 = 2; c1 = 3; c2 = 2; c3 = 3.
Dựa vào dãy biến đếm, ta hoàn toàn có thể biết được: sau khi sắp xếp thì giá trị V phải nằm từ vị trí nào tới vị trí nào. Như ví dụ trên thì giá trị 0 phải nằm từ vị trí 1 tới vị trí 2; giá trị 1 phải đứng liên tiếp từ vị trí 3 tới vị trí 5; giá trị 2 đứng ở vị trí 6 và 7 còn giá trị 3 nằm ở ba vị trí cuối 8, 9, 10:
Tức là sau khi sắp xếp:
0 0 1 1 1 2 2 3 3 3
Giá trị 0 đứng trong đoạn từ vị trí 1 tới vị trí c0.
Giá trị 1 đứng trong đoạn từ vị trí c0 + 1 tới vị trí c0 + c1.
Giá trị 2 đứng trong đoạn từ vị trí c0 + c1 + 1 tới vị trí c0 + c1 + c2.
…
Giá trị v trong đoạn đứng từ vị trí c0 + c1 + … + cv-1 + 1 tới vị trí c0 + c1 + c2 + … + cv.
…
Để ý vị trí cuối của mỗi đoạn, nếu ta tính lại dãy c như sau:
for V := 1 to M do cV := cV-1 + cV
Thì cV là vị trí cuối của đoạn chứa giá trị V trong dãy khoá đã sắp xếp.
Muốn dựng lại dãy khoá sắp xếp, ta thêm một dãy khoá phụ x1, x2, …, xn. Sau đó duyệt lại dãy khoá k, mỗi khi gặp khoá mang giá trị V ta đưa giá trị đó vào khoá xcv và giảm cv đi 1.
for i := n downto 1 do
begin
V := ki;
XcV := ki;
cV := cV - 1;
end;
Khi đó dãy khoá x chính là dãy khoá đã được sắp xếp, công việc cuối cùng là gán giá trị dãy khoá x cho dãy khoá k.
procedure DistributionCounting; {TKey = 0..M}
var
c: array[0..M] of Integer; {Dãy biến đếm số lần xuất hiện mỗi giá trị}
x: TArray; {Dãy khoá phụ}
i: Integer;
V: TKey;
begin
for V := 0 to M do cV := 0; {Khởi tạo dãy biến đếm}
for i := 1 to n do cki := cki + 1;
for V := 1 to M do cV := cV-1 + cV; {Tính vị trí cuối mỗi đoạn}
for i := n downto 1 do
begin
V := ki;
for i := 1 to n do ck := ck + 1; {Đếm số lần xuất hiện các giá trị}
end;
k := x; {Sao chép giá trị từ dãy khoá x sang dãy khoá k}
end;
Rõ ràng độ phức tạp của phép đếm phân phối là O(max(M, n)). Nhược điểm của phép đếm phân phối là khi M quá lớn thì cho dù n nhỏ cũng không thể làm được.
Có thể có thắc mắc tại sao trong thao tác dựng dãy khoá x, phép duyệt dãy khoá k theo thứ tự nào thì kết quả sắp xếp cũng như vậy, vậy tại sao ta lại chọn phép duyệt ngược từ dưới lên?. Để trả lời câu hỏi này, ta phải phân tích thêm một đặc trưng của các thuật toán sắp xếp:
TÍNH ỔN ĐỊNH CỦA THUẬT TOÁN SẮP XẾP (STABILITY)
Một phương pháp sắp xếp được gọi là ổn định nếu nó bảo toàn thứ tự ban đầu của các bản ghi mang khoá bằng nhau trong danh sách. Ví dụ như ban đầu danh sách sinh viên được xếp theo thứ tự tên alphabet, thì khi sắp xếp danh sách sinh viên theo thứ tự giảm dần của điểm thi, những sinh viên bằng điểm nhau sẽ được dồn về một đoạn trong danh sách và vẫn được giữ nguyên thứ tự tên alphabet.
Hãy xem lại nhưng thuật toán sắp xếp ở trước, trong những thuật toán đó, thuật toán sắp xếp nổi bọt, thuật toán sắp xếp chèn và phép đếm phân phối là những thuật toán sắp xếp ổn định, còn những thuật toán sắp xếp khác (và nói chung những thuật toán sắp xếp đòi hỏi phải đảo giá trị 2 bản ghi ở vị trí bất kỳ) là không ổn định.
Với phép đếm phân phối ở mục trước, ta nhận xét rằng nếu hai bản ghi có khoá sắp xếp bằng nhau thì khi đưa giá trị vào dãy bản ghi phụ, bản ghi nào vào trước sẽ nằm phía sau. Vậy nên ta sẽ đẩy giá trị các bản ghi vào dãy phụ theo thứ tự ngược để giữ được thứ tự tương đối ban đầu.
Nói chung, mọi phương pháp sắp xếp tổng quát cho dù không ổn định thì đều có thể biến đổi để nó trở thành ổn định, phương pháp chung nhất được thể hiện qua ví dụ sau:
Giả sử ta cần sắp xếp các sinh viên trong danh sách theo thứ tự giảm dần của điểm bằng một thuật toán sắp xếp ổn định. Ta thêm cho mỗi sinh viên một khoá Index là thứ tự ban đầu của anh ta trong danh sách. Trong thuật toán sắp xếp được áp dụng, cứ chỗ nào cần so sánh hai sinh viên A và B xem anh nào phải đứng trước, trước hết ta quan tâm tới điểm số: Nếu điểm của A khác điểm của B thì anh nào điểm cao hơn sẽ đứng trước, nếu điểm số bằng nhau thì anh nào có Index nhỏ hơn sẽ đứng trước.
Trong một số bài toán, tính ổn định của thuật toán sắp xếp quyết định tới cả tính đúng đắn của toàn thuật toán lớn. Chính tính "nhanh" của QuickSort và tính ổn định của phép đếm phân phối là cơ sở nền tảng cho hai thuật toán sắp xếp cực nhanh trên các dãy khoá số mà ta sẽ trình bày ở Phần 2.
Giải phóng thời gian, khai phóng năng lực